kernel.org ut i webbläsaren ChromeSammanfattning: I detta kapitel beskriver vi de avgränsningar vi har valt att göra (boken skulle bli sjukligt lång utan dessa) och försöker ge dig en överblicksbild över vad webbutveckling egentligen handlar om.
Okej (bra och seriöst ord att börja en bok med), det är nu vi ska påbörja försöket med att ge dig en överblicksbild över vad webbuteveckling är? Vad är grunderna till allt som har med webbutveckling att göra? Vad måste du som webbutvecklare veta för att lyckas bygga en webbplats? Dessa, vill vi påstå, är svåra frågor, mycket svåra. Först är det kanske lämpligt att definiera några av dessa ord.
Webbplats, webbsida och hemsida. Vi kommer i denna bok med webbplats mena hela ”platsen” (hela samlingen av dokument) medan webbsida används för ett specifikt dokument; d.v.s. en webbplats kan bestå av en eller flera (sammanlänkade) webbsidor. Ibland kommer vi även att använda ordet dokument istället för webbsida. Nationalencyklopedin är ett exempel på en webbplats, och artikeln om sköldpaddor är en webbsida från den webbplatsen. Ordet hemsida tycker vi inte om och avstår därför från att använda det, då det är otydligt vad det egentligen refererar till som Svenska datatermgruppen anmärker på.
Webbutveckling och webbdesign. Dessa två ord används för det som har med byggnationen av en webbplats att göra helt enkelt. De kan tas som synonymer, men vi anser att det finns en viss nyasskillnad mellan dem. Denna bok fokuserar nästan enbart på den tekniska delen av byggnationen av webbplatser. Vi använder därför oftast ordet webbutveckling, då webbdesign innehåller ordet design kan det tyckas att det implicerar någon form av layoutande, formtänk, färgval, hur bra dessa färger passar ihop och så vidare. Hur de olika delarna (t.ex. bilder, text eller rubriker) av din webbplats ska placeras för att inte orsaka fysiska och psykiska men hos dina besökare är inget som vi lär ut här, detta har mer med allmänt formgivningstänk och tidigare nämnda företeelser att göra. Då vi – författarna av denna bok – anser oss ganska vilsna och borttappade inom detta område har vi inga direkta referenser till lämplig litteratur om design och layoutande för vidare läsning tyvärr. Det vi kan lära ut och hoppas att du lär dig här är hur du placerar de olika delarna av din webbplats på det ställe du vill ha det, eller hur du ändrar färg på en rubrik – inte varför du gör detta (där varför skulle t.ex. kunna vara frågor som besvarades med ”eftersom att det blir snyggast så”, eller ”det passar bra ihop med det andra”).
Tänk dock på att dessa inte är allmänt accepterade normer utan bara vår tolkning av orden. Webbutveckling ser vi som allt som har med byggnationen av en webbplats att göra och webbdesign som delen av webbutveckling som specifikt handlar om design och formgivning; medan andra anser att orden är synonymer som sagt.
Webbutvecklare och webbdesigner. Dessa två ord refererar bara till någon som håller på med webbutveckling respektive webbdesign, inte helt oväntat kanske. Ord som ”web master” och relaterade är allt för vaga och kan refera till antingen någon som skriver innehållet för en webbplats eller en webbutvecklare, så vi kommer avstå från användningen av dessa.
Programmet som presenterar webbplatser för dig kallas för webbläsare. Det är troligen en sådan du använder nu. Men vad vet vi? Du kan ju t.ex. ha skrivit ut denna sida och läser den från ett papper. Detta belyser samtidigt en mycket viktig del av webbutveckling: Du kan inte göra många antagande om hur din webbplats kommer att presenteras för besökaren. Inte enbart p.g.a. att vissa besökare skriver ut webbsidan på papper – den största anledningen är att det finns så måna olika typer av webbläsare.
Oftast betyder att ”presentera” en webbplats att webbläsaren visa den på en skärm kopplad till en dator. När ordet webbläsare används är det oftast den vanligaste typen av webbläsare det refererar till, de så kallade grafiska webbläsarna. Dessa är de webbläsare som är gjorda för en dator utrustad med skärm, tangentbord och mus. D.v.s. de flesta datorer som finns i nästan varje hem. Du känner troligen till många av dem, men till de populäraste hör Internet Explorer, Firefox och Safari.
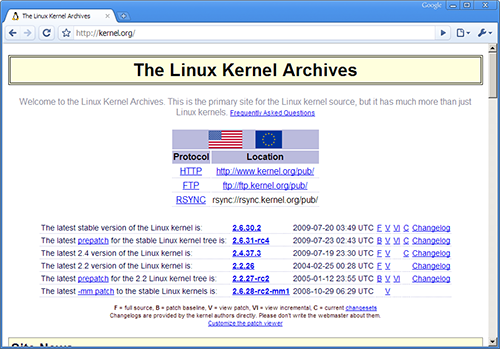
I och med att grafiska webbläsare är de överlägset vanligaste är det troligen en sådan du använder nu. Ett exempel är Chrome, som här visar webbplatsen kernel.org:
kernel.org ut i webbläsaren ChromeEn annan kategori webbläsare (som har vissa likheter med de grafiska) är de textbaserade, till skillnad mot de grafiska visar de inte bilder och stora delar av webbplatsens layout tas inte med (vilket kanske inte är så tydligt här då webbplatsen inte har någon vidare avancerad layout):
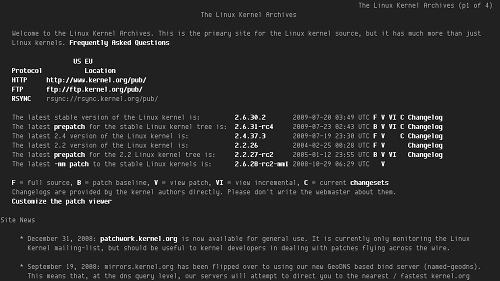
kernel.org ut i den textbaserade webbläsaren LinksSkillnaden här är framförallt att ingen mus används för att navigera på webbplatsen, all navigering sker med tangentbordet. Så det är viktigt att webbplatser fungerar för de som enbart använder tangentbord navigation.
Tänk dig nu en person med tillräckligt nedsatt syn för att inte ha nytta av någon skärm. Hur ska denna gå till väga för att kunna ta del av en webbplats innehåll? Oftast är det någon form av skärmläsare som läser upp texten som visas på skärmen. Exempelvis skulle en skärmläsare kanske säga följande om användaren besökte kernel.org (samma webbplats som innan alltså), för detta exempel har Fire Vox används:
kernel.org upp i skärmläsaren Fire Vox (klippt efter ca 7 minuter)Så när vi bygger webbplatser kan vi inte förutsätta att besökaren har en skärm inkopplad i sin dator! Inte heller denna typ av besökare har mycket nytta av en mus, utan måste istället helt förlita sig på att navigera med tangentbordet.
Även om det finns med någon typ av skärm (vilket oftast är fallet) finns det många olika storlekar och former på dessa. Ett extremt fall är mobila enheter, som t.ex. mobiltelefoner. Mobiltelefoners skärm skiljer sig en del från modell till modell, men framförallt så skiljer de sig från en ”datorskärm”, speciellt i storleksavseende som nästa bild demonstrerar.
kernel.org se ut i en mobil
Så även om det finns med en skärm inblandad kan vi inte förlita oss på att den har en speciell storlek eller utformning! Även den vanligaste typen av webbläsare, de grafiska, har ibland mycket begränsat skärmutrymme eftersom att de inte nödvändigtvis alltid använder hela skärmen (fler program kan ju vara igång och ta upp skärmplats).
Ett annat exempel visar denna video på när en blind person använder en ”refreshable Braille device”.
Som sista exempel har vi sökrobotar, de program som besöker webbplatser och lägger till dem i sin enorma samling så att de sedan går att hitta genom att t.ex. söka på Google. Dessa program skulle kunna ses som ännu en typ av webbläsare, då de ser webbplatser på ungefär samma sätt som de tidigare nämnda textbaserade webbläsarna. När du söker efter något på t.ex. Google söker du ju inte efter webbplatser med avseende på vilket utseende de har, utan det är endast webbplatsens innehåll som spelar roll då. För att få komma med i Google sökresultat, och framförallt att komma högt upp i dem, är det viktigt att även dessa botar kan tolka din webbplats.
Så, var vill vi komma med allt detta? Det vi vill säga är att detta är en av de största svårigheterna med webbutveckling, d.v.s. att få sin webbplats att fungera i så många olika typer av webbläsare. Det finns så mycket som skiljer sig åt: hur mycket skärmutrymme det finns, om bilder kommer visas, om användaren har tillgång till mus och så vidare. För att få så många besökare som möjligt till din webbplats måste den fungera för alla dessa fall.
Då en webbplats kan se ut på så många olika sätt i olika webbläsare är det svårt att skriva en bok som ska lära ut hur du kan kontrollera detta utseende på en webbplats utan att göra vissa antagande om vilken typ av webbläsare du som läser denna bok använder. När vi talar om en webbplats utseende eller resultat av exempel är det i alla fall, om inget annat nämns, hur dessa ser ut i en grafisk webbläsare som körs på en dator med normalstor skärm. Det kan kännas lustigt nu, men om man utvecklar webbplatsen för grafiska webbläsare och har i åtanke en del regler och riktlinjer som bör följas för att webbplatsen ska fungera på så många typer av webbläsare som möjligt beskriver detta ganska bra vår egen utvecklingsteknik då vi bygger webbplatser. Sedan så testas webbplatsen lite då och då i andra, mindre vanliga, typer av webbläsare för att se så att de fungerar som tänkt även där.
Fram tills nu har vi enbart fokuserat på webbläsare och hur ut- och indatametoder skiljer sig mellan olika typer av sådana. En förutsättning för att en webbläsare ska överhuvudtaget kunna visa aktuell webbsida så måste den ju hämta den från någonstans? ”Från Internet” säger du. Ja, men vad menar du med det mer precist?
För att besvara detta krävs en ny definition, denna gång av ordet webbserver. Håll i tankarna att detta är en mycket förenklad bild, men: varje webbserver har en adress, t.ex. har Googles webbserver adressen google.com (egentligen har det väldig många servrar men utifrån webbläsarens synvinkel ser det bara ut som en). När du besöker google.com genom att slå in det i adressfältet i din webbläsare (eller klickar på en länk) så skickar din webbläsare en förfrågan till webbservern som bor på adressen google.com om att få hämta förstasidan på den webbplatsen som befinner sig på den servern. Webbsidan som utgör förstasidan på webbplatsen är inget lustigare än en textfil, ofta heter förstasidan något i stil med index.html. (Varför filändelsen .html är naturlig kommer du inse senare.)
Om vi nu lugnar ner oss lite. Vi har tidigare sagt att en webbplats består utav en eller flera webbsidor. Nu vet vi alltså även att en webbsida består utav en textfil. Det är denna textfil som beskriver vad webbsidan innehåller. Ibland är det flera filer om vi räknar med bilder och annan media, men det är alltid bara en textfil som används för att beskriva webbsidan innehåll. Så vad menar vi med ordet fil? Du har troligen en ganska bra bild utav detta redan, men t.ex. ett Word-dokument är en fil, en bild är en fil, en textfil är en fil och så vidare. Så det är bara ett samlingsnamn för alla dessa. Alla webbsidor består som sagt utav en textfil (ibland säger vi även textdokument, eller bara dokument) som beskriver innehållet på sidan. Detta är en ganska vag beskrivning och vi kommer gå djupare in på hur denna textfil ser ut invändigt i nästa kapitel.
Med tanke på hur många olika typer av webbläsare och webbserverar (ja, det finns väldigt många olika typer av de också) det finns så måste det finnas någon slags överenskommelse för hur dessa två parter ska prata. På samma sätt som två människor kan kommunicera genom svenska med varandra pratar webbläsare och webbservern Hypertext Transfer Protocol (HTTP) med varandra (fast då kallas det protokoll istället för språk). Det HTTP låter oss göra är att kopiera filer från en dator till en annan, vilket är bra här eftersom att om vi kan kopiera över textfilen från servern till dig så kan din webbläsare sedan presentera webbsidan den representerar för dig. Allt detta vilket illusteras i följande bild (som inte är allt för hjälpsam, men undertecknad kände för att rita lite):
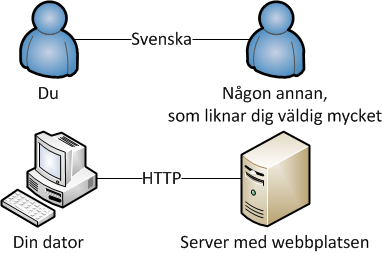
Okej, låt oss sammanfatta det hela. Webbläsaren hämtar index.html från webbservern google.com över HTTP och visar den för dig, svårare än så är det inte (typ). (När du själv bygger webbplatser kommer din egen dator fungera som webbserver och dator att köra webbläsaren på.)
En sista sak innan vi lämnar webbserverdelen ett tag nu. I adressen kan vi även skicka med en förfrågan på en specifik fil vi vill ha, t.ex. om vi vet att filen bild.jpg eller en-annan-webbsida.html finns på webbservern (t.ex. om det finns länkar dit från förstasidan) kan vi skicka en förfrågan efter dem genom att lägga till deras namn i adressen. T.ex. för att göra en förfrågan efter bild.jpg blir adressen nu google.com/bild.jpg, eller om bild.jpg finns i en mapp vid namn bilder blir adressen google.com/bilder/bild.jpg. (Exakt hur översättningen från adress till fil på webbserverns lagringsutrymme behöver inte vara så rättfram som den verkar här, men det märker inte vi som bara begär filer genom adressen.)
Ett av de absolut viktigaste koncepten inom webbutveckling är de tre lagren alla webbsidor är uppdelade i. (Kanske till och med det viktigaste.) De tre lagren består utav:
De två första lagren, ”struktur och betydelse” och ”presentation”, är enligt oss mer fundamentala än det tredje, ”beteende”. Vi kommer därför ibland referera till dessa två lager som ”de fundamentala lagren”. Struktur och betydelse-lagret behövs alltid, utan det finns det ju inget innehåll att presentera. För de två övriga lagren finns det en rad standardval som webbläsaren gör. Så låt säga att vi enbart bygger en webbplats med struktur och betydelse-lager, hur kommer då rubrikerna se ut om vi har med sådana? De flesta grafiska webbläsarna visar rubriker med större teckengrad än övrig text och oftast i fetstil. Detta är inget du behöver säga åt webbläsaren att den ska göra, utan det finns redan inbyggt där. Beroende på vilken webbläsare som används kan det vara olika standardval som gjorts (men för de vanligaste grafiska webbläsarna är de ganska lika). Du har sedan chans att byta ut dessa standardval i och med presentationslagret. Så det besökaren verkligen ser är en kombination av presentationslagret och webbläsarens standardinställningar. Beteendelagret fungerar på samma sätt. Det finns redan vissa standardsvar på vissa händelser som kan inträffa. T.ex. händelsen att besökaren klickar på en länk brukar betyda att besökaren nu istället vill besöka denna webbsidan istället. Om du inte ändrar något i beteendelagret kommer detta hända, men du kan även här ”skriva över” standardbeteende och att besökaren klickar på en länk kan resultera i precis vad du vill.
Då struktur och betydelse-lagret alltid finns med kallar vi det ibland även ”det första lagret”, då presentationslagret är ett av de fundamentala lagren blir det ”det andra lagret”, och beteendelagret blir ”det tredje lagret”. Det kan tyckas onödigt med alla dessa synonymer. Men det är p.g.a. att olika ord används av olika webbutvecklare. Så även om vi begränsade oss till ett ord för varje koncept i vår bok skulle det bara resultera i förvirring för dig då du läser någon annans text och dessa ord används istället.
Ett annat av de viktigaste koncepten när det kommer till webbutveckling är en princip eller riktlinje som handlar om just de tre lagren. Den säger att dessa lager ska hanteras så självständigt som möjligt, d.v.s. så lite inblandning som möjligt mellan dem. Det ska alltså finnas tre separata delar av webbplatsen som man kan peka på och säga ”detta är struktur och betydelse-lagret” och ”här ser vi presentationslagret” och så vidare, så att allt inte blandas ihop till en enda röra. Separera ”struktur och betydelse från presentation” är ett mycket vanligt uttryck när man enbart fokuserar på de två fundamentala lagren. Denna princip är viktig och bra för både dig som utvecklare och dina eventuella besökare. Att tala mer konkret om hur detta går till går inte ännu då vi inte gått igenom hur dessa lager ser ut, så du får för tillfället nöja dig med att komma ihåg denna mycket viktiga (vi har svårt att understryka hur viktigt detta är) princip och tänka på den under tiden då du informeras om hur de olika lagren är uppbyggda och fungerar. Det är samtidigt kanske inte så motiverande för dig att bara behöva godta detta som en centralt och grundläggande koncept utan argument om varför det skulle vara så, men utan mer kunskap om lagrens strutkur kan vi inte gör det ännu; men det kommer, vi lovar.
Så sammanfattat blir det alltså: separera de tre lagren i så stor utsträckning som bara möjligt.
Varje lager har ett språk associerat till sig. Dessa språk är byggda så att en dator kan tolka dem, och följer därför mycket striktare regler än ett vanligt naturlig språk (som t.ex. svenska). De fundamentala lagrens associerade språk är mycket enkla och i viss mening ganska lika, medan beteendelagrets språk skiljer sig helt från dessa två. Beteendelagrets språk är ett fulltaligt programmeringsspråk (ibland kallat programspråk), och kräver kunskap runt sådana för att kunna hanteras. Vi kommer därför i denna bok nästan uteslutande att fokusera på de fundamentala lagren och nöja oss med det standardbeteende som finns inbyggt i webbläsaren (som i de flesta fall duger alldeles utmärkt). Att även ta med detta lager skulle betyda att vi även måste skriva en introduktionsdel till programmering i allmänhet. Detta vill vi inte då det är en nästan omöjligt svår uppgift. Det finns de som lyckats ganska bra och dessa kommer vi referera till när vi tar en närmare koll på beteendelagret i slutet av grunddelen av denna bok. Så tills dess kommer vi mer eller mindre glömma att detta lager finns och enbart fokusera på de två andra.
Så varför vill vi inte kalla de fundamentala lagrens språk för programmeringsspråk? Först och främst, vad är ett programmeringspråk mer precist? Wikipedias definition av ett programmeringsspråk anser vi vara helt okej:
Ett programmeringsspråk är ett artificiellt språk designat för att uttrycka beräkningar som kan utföras på en maskin, i synnerhet en dator. Programmeringsspråk kan användas för att skapa program som kontrollerar maskinens beteende eller för att uttrycka algoritmer [...]. [egen översättning av revision 368555021]
Detta beskriver inte vad de fundamentala lagrens språk gör alls. Vi skriver inte kod för att utföra beräkningar (tänk på att vi inte bara menar addition och subtraktion av tal här), vi bara talar om vad olika delar av en webbsida består utav och ska presenteras (vilket inte kräver något sätt att uttrycka beräkningar i språken). Därför brukar dessa två språk inte vanligen kallas för programmeringsspråk.
För att förstå presentationslagret måste du först förstå strutkur och betydelse-lagret, eftersom att det förstnämnda talar om hur det sistnämnda ska presenteras för användaren. Så att börja med det sistnämnda verkar lämpligast.
Struktur och betydelse-lagrets språk heter ”Hypertext Markup Language” och förkortas HTML. Detta språk är ett märkspråk, då det används för att märka upp olika delar av en webbsida och tala om vad de olika delarna betyder. Vi har tidigare nämnt att en webbsida inte är något annat än en samling filer. För att bygga ett strutkur och betydelse-lager räcker det med en vanlig textfil, och såhär kan en simpel webbplats se ut:
<!doctype html>
<html>
<head>
<title>A very simple document</title>
</head>
<body>
<h1>The worst web page ever</h1>
<p>This is just a very simple document with a header and a small text paragraph that states exactly that.</p>
</body>
</html>Vi skriver på engelska till en början eftersom att vissa extrasteg behövs för att å, ä och ö ska fungera (och andra ”specialtecken”).
Ett ord omslutet med < och > kallas för tagg, t.ex. <title>. Det finns två typer av taggar: start- och sluttag. En start- och en sluttag bildar tillsammans med innehållet som står mellan dem ett element. Starttaggen talar om var elementet börjar och sluttagen talar om var elementet slutar; ibland säger vi att sluttagen stänger elementet. I vissa fall är sluttaggen frivillig, men detta struntar vi i just nu. Även om det skulle fungera att utelämna vissa sluttaggar i några av våra tidigare exempel så tar vi med dem för att du i detta skede slippa lära dig reglerna för när detta är okej eller ej. (Det finns vissa element där sluttagen är förbjuden, dessa kallas för tomma element, vi kommer in på dessa senare.) <title> är som sagt en tagg, mer exakt är det en starttag. En sluttag ser ut på samma sätt fast innan namnet finns det ett /, t.ex. </title>. Alltså är följande ett helt element, då den består av en starttag, innehåll och en sluttag:
<title>A very simple document</title>Det är viktigt att du lär dig att skilja på termerna element och tagg, det är inte helt ovanligt att dessa blandas ihop.
Vi sade förut att HTML är ett märkspråk eftersom att det används för att märka upp olika delar av en webbsida och genom detta talar om vad de olika delarna betyder. Det är detta taggar används till. title-elementet från exemplet talar om för webbläsaren att webbsidans titel är ”A very simple document”. Denna visas vanligen i fönsterkanten i toppen av fönstret i grafiska webbläsare.
Det finns en del andra element med i webbsidan. Vad betyder de då? h1-elementet talar om att dess innehåll är en rubrik (i nivå 1) och p betyder ett textstycke. Även elementen html, head och body syns till. Dessa tre element utgör grundstrukturen för alla webbsidor och är alltid där. Vi ser även att dessa element inte bara har text som innehåll (alltså det mellan start- och sluttagen). Det finns andra element i elementet, dessa element kallas nästlade element. Bl.a. är head- och body-elementet nästlade i html elementet, och h1- och p-elementet är nästlade i body-elementet. Elementen har följande betydelse (tänk på att följande är något förenklat, men stämmer ganska bra, det är svårt att ge en kort och heltäckande definition):
html är ett element som talar om att ”detta är en webbsida” och omsluter alltså alla andra element.
head är ett element som innehåller alla element som innehåller data om webbsidan, metadata (”data om data”) alltså, snarare än innehåll som besökaren ser direkt. T.ex. finns webbsidans titel här, men inte webbsidans rubriker, alltså det besökaren ser direkt.
body är elementet som innehåller webbsidans egentliga innehåll, så som rubriker och textstycken.
Relationen mellan element i en webbsida är det ganska hjälpsamt att representera som ett s.k. träd:
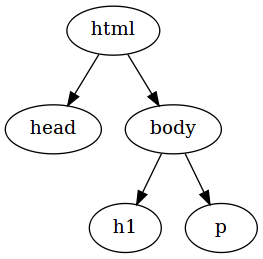
Varje cirkel representerar ett element, ibland så kallar vi elementen för noder när vi tänker oss denna trädform (ibland även utanför trädsammanhang). Pilarna mellan noderna representerar att ett element är nästlat i ett annat, t.ex. så är head-elmentet nästlat i html-element som vi nämnde tidigare. Det visar sig att denna representation av en webbsida är mycket användbar för presentationslagret senare. Det ger även en hjälpsam överblicksbild över webbsidans struktur. Så när du läser HTML-kod är det ofta ett bra tillvägagångssätt att tänka dig ett sådant här träd för att förstå vad koden betyder.
Ordet träd och nod kommer från grafteorin, och där ifrån ska vi låna en rad andra ord. Många känns troligen igen från s.k. släktträd. Pilarna mellan noderna kallas för (riktade) bågar, som är ett ord vi inte har så mycket nytta av utöver att definiera andra ord med. Här följer en lista med viktiga ord vi kommer behöva senare.
p ett barn till body.
p en ättling till html, men ej ett barn. body är både ett barn och en ättling till html. html är även förfader till bl.a. head och h1 (html är förfader till alla element faktiskt).
Dessa är främst användbara när vi kommer till presentationslagret senare.
Trädet som representerar HTML-dokumentet är dock inget träd i grafteoretisk mening, då ordningen på noderna spelar roll. I koden så kommer head- före body-elementet om dokumentet läses uppifrån och ner. I grafen ligger head-noden till vänster om body-noden. Detta stämmer alltid, om elementet kommer före ett annat element och de har samma förälder så kommer den första elementets nod ligga till vänster om den andra elementets nod. Detta blir viktigt i presentationslagret senare.
Nu är det bara en del av webbsidan som återstår, nämligen första raden: <!doctype html>. Detta är bara en historisk kravleva som alla webbsidor måste börja med, vi får acceptera att det bara är så för tillfället och återkomma till det senare. Det är föressten inte ens en tagg, men nu glömmer vi den.
Det som är så bra nu är att du nästan kan alla HTML du någonsin kommer att använda. Svårare är så är det inte. Det finns vissa element som inte består utav en start- och sluttag, och ett koncept som kallas för attribut som används för att tilldela element extra egenskaper; men utöver det är ovanstående ganska heltäckande. Det du kan nu och det vi just sade är allt du behöver kunna om HTML, förutom vilka element som finns såklart. Vilka element som finns och vad dessa betyder kommer vi in på i senare kapitel, det blir mer eller mindre bara en lång lista med vad de betyder och på vilket sätt det är lämpligt att använda dem.
Vi vet att en webbsida består av en textfil och vi vet nu även vad denna textfil ska innehålla. Då borde det inte finnas något som stoppar oss från att bygga en fult fungerande webbplats (bestående av en enda webbsida, men ändå)? Det är precis det vi ska göra nu.
Hur du ändrar i textfiler på din dator beror på vilket operativsystem du använder, det kan vara t.ex. Microsoft Windows, GNU/Linux eller Mac OS.
Då en webbsida består av en textfil är det inte helt oväntat att du behöver du ett program du kan redigera text i, en s.k. textredigerare. Troligen har du redan tillgång och kunskap om en sådan, om du inte har det så finns Notepad++ som alternativ för Windows-användare, och om du använder något annat operativsystem så följer troligen en tillräckligt bra textredigerare med din skrivbordsmiljö (t.ex. finns gedit för GNOME-baserade GNU/Linux-installationer, som bl.a. Ubuntu). Det finns allt för många olika operativsystem för att vi ska kunna lista upp alla här, så om du inte är intäckt av de valen som erbjudits så får du tyvärr lösa detta problem på egen hand, men det borde inte utgöra något större problem.
En kort notis som kan göras här är angående grafiska verktyg för att utveckla webbplatser, så kallade What You See Is What You Get-program (WYSIWYG-program). Alla dessa producerar värdelös kod och inget en seriös webbutvecklare använder, så dessa kommer inte nämnas mer. Det är bl.a. väldigt svårt att separera de två fundamentala lagren på ett bra sätt när det du ser är hur det första lagret ser ut efter presentationslagret är applicerat på det snarare än varje lager för sig i textform, och textformen är omöjligt svår att läsa eftersom att det är en dator som producerat den.
Börja med att skapa en mapp på skrivbordet och kalla den webbutveckling eller något sådant. Sedan skapar du en fil (i vissa operativsystem genom att högerklicka och välj något i stil med ”ny textfil”) med namnet index.html, det är filändelse som är det viktiga här övriga namn kan du egentligen välja hur du vill.
Windows-användare (och möjligen andra), i standardutförande så gömmer Windows filändelser på filer. Du vill troligen stänga av detta om du inte redan gjort det för att slippa förvirring huruvida en fil är en .txt- eller .html-fil. I till exempel Windows XP gör man detta genom att gå till ”Kontrollpanelen” (se till att den visas i ”klassiskt läge”) → ”Mappalternativ” → ”Visning” och avmarkera ”Dölj filnamnstillägg för kända filtyper”.
Öppna den nya filen i din valda textredigerare och skriv av för hand webbsidan från exemplet ovan. (Det är bra att skriva koden själv istället för att bara kopiera den för att det blir oftast enklare att komma ihåg det senare då.) Spara filen och öppna den i din webbläsare. (I vissa operativsystem genom att dubbelklicka på index.html-filen.) Testa att ändra lite i filen, t.ex. lägga till ett till textstycke eller rubrik. Spara och glöm sedan inte att uppdatera webbsidan i din webbläsare, oftast finns det någon knapp i webbläsaren som laddar om sidan; alternativt brukar F5-tangenten ha samma funktion i många webbläsare.
Webbsidan borde se ut ungefär såhär i din webbläsare:
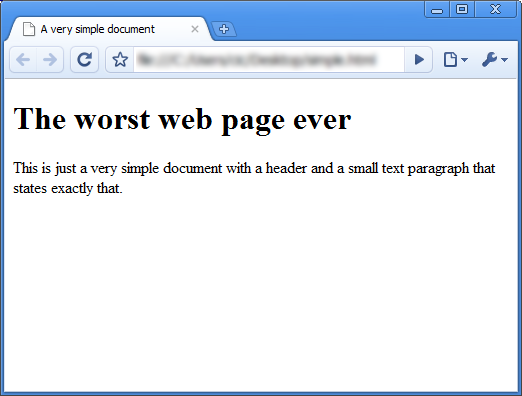
Som skärmdumpen visade, och troligen även din egen webbläsare, så har rubriken större teckengrad än textstycket och mellan rubriken och textstycket så finns det ett mellanrum. Dessa har alla med presentationen av webbsidan att göra, och de som nämndes här kommer från det webbläsarens standardinställningar för presentationslagret. Vi ska nu gå igenom hur dessa utseendeegenskaper kan ändras.
Som sagt så har varje lager ett språk associerat till sig, detta gäller även såklart för detta lager. Språket heter ”Cascading Style Sheets” och förkortas ”CSS”. Följande rad är en bit CSS-kod och kommer göra så att rubriken får röd textfärg:
h1 {color:red;}Syntaxen för CSS är precis som HTML mycket enkel, och all kod följer detta mönster:
selektor {egenskap1:värde1; egenskap2:värde2;}Selektor talar om vilka element (noder i det tidigare nämnda trädet) som kommer påverkas av det följande blocket. Selektorn och blocket kallas tillsammans för regelmängd. Blocket består sedan av en mängd egenskaper och värden till dessa, egenskaperna och dess värden talar om hur presentationen av de (av selektorn) matchade elementen kommer att påverkas. Vi ser även att egenskaper i blocket åtskiljes med ett semikolon, ”;” alltså.
Det sista semikolonet kan utelämnas, d.v.s. det efter den sista egenskapen. Men det kan skapa problem när du glömmer att lägga till det när du senare när du kommer på att regelmängden skulle behöva fler egenskaper, och syntaxfel uppstår.
Hur du formaterar din kod spelar ingen roll, du kan lägga in några radslut om du känner för det. Hur många radslut som är lämpliga är en smaksak och skiljer sig från webbutvecklare till webbutvecklare. T.ex. kommer denna regelmängd betyda samma sak som den tidigare, även att den innehåller fler radslut:
selektor {
egenskap1:värde1;
egenskap2:värde2;
}Nästan all CSS-kod som finns ser ut såhär, det som återstår nu är att lära sig vilka olika selektorer det finns och vilka egenskaper som går att ändra på, men även hur alla dessa smådelar ska kunna kombineras ihop till att skapa en färdig webbplats. Nu nöjer vi oss nu med att titta på en av de simplaste selektorerna och att tilldela de matchade elementen en annan textfärg.
När vi ska förstå hur selektorer fungerar är trädet av element från webbsidan mycket hjälpsam. Tänk dig selektorn som ett sätt för dig att välja ut ur trädet vilka element du vill påverka med efterföljande block. Här är trädet för vår första webbsida igen:
För att ta några exempel så kan vi som vi tidigare sett matcha alla element av en viss typ, selektorn för det är väldig enkel: det är bara elementets namn. Vi kan även ta hänsyn till trädets struktur i selektor, så som ”matcha alla p-element som är har body som förfader”, även detta är enkelt: body p bara. Exempel på mer avancerade selektorer kommer vi in på senare i kapitlet om CSS.
Så hur kopplar vi CSS:en till vårt HTML-dokument? Det finns en rad sätt, men det simplaste är att skriva CSS:en i ett eget element i HTML-koden, elementet heter style:
<!doctype html>
<html>
<head>
<title>A very simple document</title>
<style>
h1 {color:red;}
p {color:green;}
</style>
</head>
<body>
<h1>The worst web page ever</h1>
<p>This is just a very simple document with a header and a small text paragraph that states exactly that.</p>
</body>
</html>Resultatet är inte överdrivet imponerande:
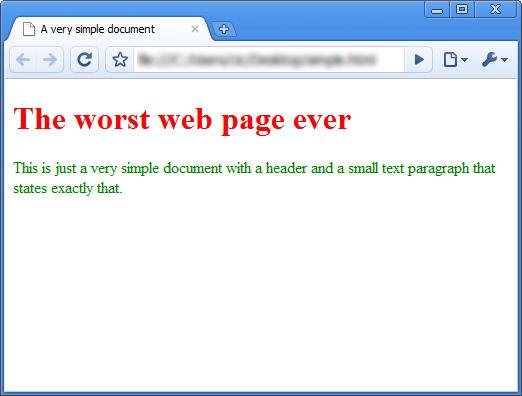
Inte helt oväntat ska style-elementet vara inuti head-elementet, eftersom att det är information om webbsidan snarare än innehåll och struktur. Rubriken bör hur som helst vara röd nu och textstycket grönt.
Det vanligaste sättet att koppla CSS till en webbsida är att ha CSS:en i ett eget dokument (textfil), och sedan från webbsidan peka på det dokumentet och säga ”använd detta CSS-dokument för presentation av mitt innehåll”. Detta är speciellt bra när du har en webbplats bestående av fler webbsidor, eftersom att du bara behöver ändra i ett CSS-dokument (fler webbsidor kan peka på samma CSS-dokument) istället för en gång per webbsida om du t.ex. vill ändra färgen på alla rubriker.
Vi sade tidigare att ett av de viktigaste koncepten är separation av de tre lagren. Vad menar vi med detta då? Det ser ju inte så svårt ut, det är ju helt olika språk!
För att kunna svara på detta behövs en kortare historielektion. Från början fanns det bara ett lager, som skötte allt. Detta lager liknar det vi idag kallar struktur och betydelse-lagret, i den mening att lagret enbart bestod av HTML. HTML hade alltså hand om allt då, både sin nuvarande roll men även presentation och beteende. Många av dessa delar finns kvar i HTML idag. Så det gäller att undvika dessa, för att inte råka blanda ihop lagren.
Vi löser detta problem genom att inte nämna delarna av HTML som används för att styra presentation och beteende. Om du någongång sertill sådana delar av HTML är det bara att ignorera dem helt enkelt.
Vi har undvikit frågan länge nog nu, varför vill vi göra denna separation av lagren? Det har två sidor, en för sig om utvecklare och en för besökarna. Vi börjar med fördelarna för dig.
Genom att ha allt samlat på ett ställe vet du precis var du ska leta för att hitta det du ska ändra på när du vill göra det. Detta kanske inte låter som någon stor sak just nu, men tänk dig att du byggt en webbplats bestående av tusentals webbsidor; då är lite ordning och redan inte helt fel. När allt blandas ihop till en enda röra är det tillslut ingen som kan förstå vad koden gör, inte ens du som skrivit den efter ett tag. CSS-kapitlet börjar med ett mer konkret exempel på vad vi menar med detta, det har att göra med det vi tidigare nämnde med att flera webbsidor kan dela på ett CSS-dokument.
Så besökarna, varför bryr de sig om hur koden ser ut? De ser ju aldrig den? Det är sant, de bryr sig inte om den. Men då lagren är separerade på korrekt sätt kan deras webbläsare hantera webbsidan bättre än om allt var blandat i en stor röra. Exemplet med skärmläsaren i början av kapitlet är bra här. När webbsidan läses upp så är hur saker ser ut av föga intresse för personen som lyssnar, denna vill enbart höra på webbsidan struktur och betydelse. Så skärmläsaren måste kunna välja ut dessa delar och strunta i resten, om ansvarig webbutvecklare har blandad ihop lagren är det enkelt gjort att slarva och istället för att märka upp att en rubrik är en rubrik med ett h1-element istället bara förstora teckengraden och göra texten fet. Då finns det inget kvar som låter skärmläsaren förstå att det är en rubrik!
Vi har redan berört hur HTML kan råka användas för presentation, men gäller även motsatsen? Kan CSS råka användas för struktur och betydelse? Ja, det går även det. Exemplet blir liknande det föregående. Vi skulle kunna byta ut vårt h1-element mot ett p-element i den simpla webbsidan som vi använde för att testa lite CSS på tidigare. Med hjälp av CSS kan vi sedan ändra det första p-elementet på webbsidan så att det ser ut som en rubrik. Problemet med detta är att det inte blir en rubrik, det ser bara ut som en (det enda sättet att göra en rubrik är att använda ett rubrikelement, så som h1). När en skärmläsare ser detta förstår den inte att detta är en rubrik och hanterar den istället som ett textstycke. Det är svårt att få en överblick av webbsidan med en skärmläsare, men om alla rubriker är uppmärkta på sådant sätt att skärmläsaren kan hitta dem går det iallafall att t.ex. generera en innehållsförteckning på så sätt. Även funktioner som t.ex. ”hoppa till nästa rubrik” och så kan byggas in i skärmläsaren.
Som vi sade i början så fungerar Googles sökrobotar inte helt olikt dessa skärmläsare, så om din webbplats inte fungerar bra med skärmläsare blir troligen även Googles sökrobotar förvirrande när de besöker din webbplats och din placering i sökresultatlistan försämras kraftigt.
Det finns mer invecklade och svårupptäckta fall än dessa såklart, som vi kommer se igenom hela boken. Denna princip ska alltid hållas i tankarna, i form av ”hör denna del verkligen till det lagret jag kommer lägga till den i nu”.
Vi har sagt att HTML och CSS inte är några programmeringsspråk, och därför inte kan utföra några slags beräkningar. Ändå så kan Google söka på Internet efter ord på webbplatser, detta måste ju betyda någon form av beräkningar. Är det detta mystiska tredje lager som utför dessa beräkningar? Nej, det är det inte. Dessa beräkningar Google utför måste göras på deras webbserver (som du förhoppningsvis minns vad det betyder från tidigare del av detta kapitel). Detta leder till nästa stora uppdelning av webbutveckling. Webbutveckling brukar delas upp i de två kategorierna klientwebbutveckling och serverwebbutveckling (det finns många synonyma termer för dessa två), även klientsidan och serversidan är vanliga att prata om. Vi tar som vanligt en i taget.
Det vi gått igenom i detta kapitel är klientsidan, det vill säga de tre lagren. Så när vi sagt ”webbutveckling” har vi underförstått egentligen menat ”klientwebbutveckling”. Det är saker som har att göra med webbläsaren: hur den tolkar struktur och betydelse-lagret, hur presentationslagret gör att webbsidan ser ut i slutändan och så vidare. Även beteendelagret är med här, det lagret har som sagt ett fulltaligt programmeringsspråk att tillgå. Med det går det att utföra beräkningar på klientsidan. Det viktiga här är att beteendelagrets språk körs efter webbsidan har hämtats från webbservern, och den kan inte hämta information där ifrån. Så den måste klara sig med det som finns på din lokala dator, det är alltså bara din dator beteendelagret kan påverka. (Egentligen kommer denna parentes troligen förvirra dig mer än den hjälper men: det finns sätt att ladda ner ny information i bakgrunden (dolt för användaren) från webbservern efter att webbsidan har hämtats och sedan t.ex. visa denna nyhämtade information på webbsidan; denna teknik kallas Ajax och vi kommer gå in på den när vi pratar om det tredje lagret. Detta strider inte mot det vi säger, det är bara ett sätt att dölja för användaren att ny information hämtas från webbservern. Som sagt, om du inte lyckas avkoda detta nu så bara ignorera det.)
På serversidan finns inte de tre lagren. Någon generell överblick över hur serversidan ser ut går nästan inte att göra, då det finns väldigt många olika modeller för hur det kan se ut. Något speciellt associerat språk finns inte heller, det finns stor valfrihet i det avseendet på serversidan (för att ta några exempel: Ruby, Python, Java och PHP). Det vi kan göra är att ta ett exempel och med det försöka visa hur serversidan fungerar och skiljer sig från klientsidan.
I detta exempel ska vi studera hur en besökarantalräknare kan fungera. Först och främst måste vi ha någonstans att spara antalet besökare, detta görs vanligen i en databas. En databas är bara ett ställe där vi kan spara data. En naturlig fråga är då, är denna databas placerad på klient- eller serversidan? Det finns faktiskt inget val här, den måste placeras på serversidan. Klienterna (webbläsarna) kommunicerar aldrig direkt med varandra, all kommunikation sker genom webbservern. Så om vi vill ha information som en klient kan påverka (antalet besökare höjs ju varje gång en webbläsare gör en förfrågan och påverkar därmed databasen) och andra kan se (”se” i den mening att den kommer vara en del av en webbsida) måste den sparas på serversidan.
Så åter till hur räknaren fungerar. När webbservern får en förfråga från en webbläsare om att få ladda ner webbsidan börjar den med att hämta filen som är webbsidan. Detta är dock ingen HTML-fil, det är en serverskriptfil (ibland kallas filer som körs av en dator för program, ibland för skript, skillnaden är inte viktigt här (vad skillnaden är beror även på vem du frågar)). Denna serverskriptfil körs sedan, som ett vanligt program; men resultatet av körningen är inte som i programmen du kanske är van vid att köra på din egen dator. Istället för att visa t.ex. ett fönster eller spela upp ljud så producerar filen som körs istället en HTML-fil! Det är denna fil som webbservern sedan skickar till webbläsaren som frågade efter filen. Detta kan låta lite komplicerat, att vi inte själva skriver HTML-koden utan istället skriver ett program som skrivet HTML-koden åt oss. Detta är dock nödvändigt för att inte behöva svara med samma webbsida varje gång en webbläsare besöker samma adress. Det är såhär nästan alla webbplatser fungerar idag. Ingen skriver statiska webbplatser längre nästan, nästan alla är dynamiska. För att kunna skriva program som producerar webbsidor måste du såklart ha koll på de klientwebbutvecklingen först, så klient- kan ses som ett förkunskapskrav till serverwebbutveckling (det finns dock delar på serversidan som du skulle kunna göra som inte har någon direkt inblandning med klientsidan, t.ex. vara databasexpert och ha total koll på hur databaser ska utformas för optimal prestanda).
Andra exempel på dynamiska webbplatser är när någon form av formulärhantering är inblandad. I HTML går det att skapa formulär, bl.a. fält för att mata in text eller kryssrutor. I HTML går det dock inte göra så att formuläret gör något (det går ju inte uttrycka beräkningar i HTML). Detta sköter serversidan. HTTP (det språket, eller protokoll) som används för kommunikation mellan webbläsare och webbserver kan göra fler saker än att bara begära webbsidor och svara på sådana förfrågningar. I en begäran av en webbsida kan webbläsaren skicka med det användaren har skrivit in i ett formulär. Ett serverskript kan sedan köras på serversidan som tar hand om denna formulärdata, och kontrollerar så att alla fält är korrekt ifyllda. Om fälten är korrekt ifyllda kan serverskriptet spara formulärdatan i en databas för senare användning och generera en webbsida som säger till användaren att allt gick bra. Om något inte stämmer i formuläret kan serverskriptet istället generera en webbsida som talar om vad som är fel och vad användaren måste göra om.
Med hjälp av endast detta går det bygga en enkel blogg. Vi kan ha ett serverskript som tar emot data och kontrollerar den, och om den är okej sparar den i en databas. Sedan kan vi ha ett annat serverskript, troligen startsidan, som hämtar informationen från databasen och skriver ut den så att användaren kan se den.
Denna bok fokuserar på klientsidan då som sagt det kan ses som ett förkunskapskrav för att kunna bygga saker på serversidan, så det känns som den naturliga sidan att börja med. I slutet av boken kommer dock en utblick med lästips om hur du kan gå vidare för att lära dig hur webbutveckling på serversidan går till.
I detta kapitel har vi gått igenom nästan alla områden vi kommer beröra i boken (och även en del som vi inte kommer behandla mer!). Så det är omöjligt att du förstått allt på en gång. Det viktigaste från detta kapitel är dock: