Sammanfattning: Detta kapitel beskriver CSS närmare, det språk som används för att styra presentationslagret. Hur grunderna fungerar och även centrala koncept så som kaskad och arv. Fokus ligger på syntax och funktionalitet som CSS erbjuder, inte vilka egenskaper som finns tillgängliga för att ändra utseendet på din webbplats. Kapitlet avslutas med en del praktiska tips och utsmyckning av webbsidan från föregående kapitel.
Presentationslagret består av ”Cascading Style Sheets”, eller bara ”CSS”. I detta kapitel ska vi ta en närmare koll på vad detta lager har att erbjuda. Det är CSS som styr allt utseende på din webbplats, allt från vilken teckengrad rubriker har till hur menyn ska vara placerad relativt övriga dela av webbplatsen. Hur vi bygger och placerar menyer och kolumnlayouter kommer vi gå in på i nästa del av boken, som heter Design. I nuvarande del fokuserar vi på grunderna: hur önskade element välj ur trädet, hur kaskad och arv fungerar (och vad det överhuvudtaget är) och en rad egenskaper vi kan påverkar webbplatsens text utseende (vilket kommer i nästa kapitel).
Denna sektion är ganska kort och kommer kanske bli längre någon gång.
Precis som HTML finns CSS i olika utgåvor. Fast i ett avseende skiljer sig dessa avsevärt. CSS har flera olika lager snarare än versioner som ersätter de tidigare. Det finns idag tre nivåer av CSS: CSS1, CSS2 och CSS3. Där CSS2 bygger vidare på CSS1, och CSS3 bygger vidare på CSS2. Populära webbläsare idag har fullt stöd för CSS1 och nästan fullt stöd för CSS2. (När vi säger CSS2 menar vi egentligen CSS2.1, det är inte så vikigt.) CSS3 är inte klart ännu, men det finns en del stöd för det i vissa webbläsare. Vi kommer därför främst inrikta oss på CSS1 och CSS2.
Då de två fundamentala lagren är separerade måste vi ha något sätt att knyta ihop dessa på och tala om vilket presentationslager som ska användas till vårt nuvarande struktur och betydelse-lager. Det finns tre sätt att göra detta på:
Externa CSS-dokument är alltid att föredra för att det sparar bandbredd i och med att besökarens webbläsare lagrar stilmallen lokalt och slipper ladda ner den varje gång den besöker webbplatsen. Med bandbredd syftar man på hur mycket information/data servern måste skicka till sina besökare. Din webbläsare sparar alltså filer lokalt på din dator när du laddar ner de olika delarna av en webbplats, t.ex. bilder och andra externa dokument, för att den ska slippa ladda ner samma fil flera gånger. Detta gör den för att vara snäll mot servern genom att minska dess belastning, och sedan för att det ska gå snabbare för dig att bläddra mellan sidorna på webbplatsen, eftersom att man inte behöver ladda ner samma fil flera gånger.
Om vi istället skulle ha stilmallen internt skulle webbläsaren vara tvingad att ladda ner samma stilmall varje gång en webbsida från webbplatsen laddades ner, eftersom att båda ligger i samma fil.
För att göra en extern stilmall börjar vi med att göra en fil vid namn style.css med följande innehåll:
p {color: red;}För att koppla stilmallen till vårt kommande HTML-dokument måste vi använda oss av ett nytt element, nämligen link:
<link rel="stylesheet" href="style.css">link-elementet ska ligga inom head-elementet eftersom att det är information om webbsidan snarare än en del av den.
rel="stylesheet" är vilket förhållande (rel är en förkortning av relationship) det här dokumentet har till det vi länkar till, stylesheet ska användas som värde eftersom det är en stilmall vi länkar till.
href="style.css" talar om var dokumentet (CSS-dokumentet i detta fall) finns. Om vi som här skriver style.css menar vi filen style.css i samma mapp, om vi istället skulle ha använt css/style.css menar vi style.css i mappen css till exempel. Vi kommer att gå djupare in på hur detta fungerar när vi går igenom hur man skapar länkar i HTML, men det är ett senare kapitel.
Skapa sedan ett HTML-dokument i samma mapp med följande innehåll:
<!doctype html>
<html>
<head>
<title>Ett exempeldokument för att testa CSS med</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<p>Här är bara ett testtextstycke!<p>
</body>
</html>Om allt gick rätt till ska nu texten i dokumentet vara färgad röd.
Interna stilmallar är som sagt ungefär samma sak som externa, fast stilmallen är istället inbakad i HTML-dokumentet. Som vi såg i introduktionskapitlet så används elementet style för att baka in en stilmall i ett HTML-dokument:
<!doctype html>
<html>
<head>
<title>Ett exempeldokument för att testa CSS med</title>
<style>p {color:red;}</style>
</head>
<body>
<p>Här är bara ett testtextstycke!<p>
</body>
</html>För att utöver bandbreddsbesparingar kunna motivera varför du ska använda externa stilmallar kommer vi gå igenom följande exempel på ett vanligt problem vars lösning kan generaliseras till en viktig princip inom mjukvaruutveckling. Vi utlovande även i introduktionen ett konkret exempel på varför det är en bra vana att separera lagren i så stor utsträckning som möjligt. Tursamt nog täcks även detta in här.
Vår utgångspunkt är att CSS är en dålig idé och vi skulle klara oss bra med enbart ett lager istället för de två fundamentala som finns nu. Vi ska nu se hur detta leder till en sämre värld att leva i. Så, skulle det inte fungera att använda attribut på elementen istället för CSS att tala om hur de bör se ut? T.ex. skulle vi kunna införa ett attribut som heter color som gick att applicera på alla element och som talade om vilken färg texten i det elementet fick:
<p color="red">Lite text som då skulle bli röd, notera att detta är låtsas-HTML!</p>Visst, det fungerar. Det inte bara fungerar, det var så det gick till, förr i tiden, innan CSS. För att inse att detta är en sämre lösning än dagens behövs dock fler element. Föreställ dig följande: Du vill ha alla rubriker i blå färg på hela din webbplats, som kan bestå av tusentals webbsidor. En av de webbsidorna skulle kunna se ut såhär:
<!doctype html>
<html>
<head>
<title>Mall för hemliga dokument</title>
</head>
<body>
<h1 color="blue">Mall för hemliga dokument</h1>
<p>Lägg till hemlig information här.</p>
<h2 color="blue">Hemlig information</h2>
<p>Här behövs det mer hemlig information.</p>
</body>
</html>Låt säga att du bestämmer dig för att röd färg på alla rubriker skulle vara snyggare. I exempeldokumentet måste du bara ändra på två ställen, men tänk sedan på övriga webbsidor på din webbplats, då måste du ändra i alla, hela databasen på (låt säga) 700 hemliga dokument. Det är denna del som suger med att göra såhär. Föreställ dig istället att du använt CSS för att tala om hur olika delar av dokumentet skulle se ut, då gör du ett CSS-dokument som styr utseendet på de 700 hemliga dokumenten. Webbsidorna innehåller då ingen information om hur strukturen ska presenteras, men innehåller istället ett link-element som talar om vilket CSS-dokument som ska användas (samma CSS-dokument används alltså till alla hemliga dokument):
<!doctype html>
<html>
<head>
<title>Mall för hemliga dokument</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Mall för hemliga dokument</h1>
<p>Lägg till hemlig information här.</p>
<h2>Hemlig information</h2>
<p>Här behövs det mer hemlig information.</p>
</body>
</html>I vårt CSS-dokument talar vi om att h1- och h2-element ska ha röd färg.
h1 {color:red;}
h2 {color:red;}När du nästa gång vill ändra färg på rubrikerna så behöver du bara ändra på dessa två rader istället för en gång per rubrik, vilka är utspridda i 700 filer.
Denna princip, att inte representera samma information på flera olika ställen är ett centralt och viktigt koncept inom mjukvaruutveckling och kallas där för Don't Repeat Yourself (DRY). Du bör alltid tänka på detta, d.v.s att aldrig har samma information representerad på flera olika ställen. Det blir bl.a. som vi sett mycket jobbigare att utföra ändringar när vi vill göra sådana. (Wikipedia har en kort artikel om DRY-principen om du vill läsa mer.)
Så vad har detta med externa och interna stilmallar att göra? Och vad hände med de s.k. inline-reglerna? Om DRY-principen tas i åtanke ser vi att interna stilmallar är duplicering av information då samma stilmall finns sparad i flera olika filer. Om varje dokument skulle ha en kopia av stilmallen skulle det inte vara mycket bättre än att använda det påhittade color-attributet när du ska göra färgändringen på alla rubriker.
Vi har tidigare sagt att en selektor används för att välja ut vilka element på webbsidan (eller noder i trädet annorlunda uttryckt) som ska påverkas av efterföljande regelblock. Inline-relger ger oss möjlighet att istället direkt skriva stilregler för ett element i aktuellt elements style-attribut. T.ex. kommer följande göra textstycket i fråga grönt:
<p style="color:green;">Ännu ett textstycke med svårläst text p.g.a. dåligt färgval</p>Likheterna med det påhittade color-attributet är inte svåra att se. Det blir ju precis samma sak! Det spelar ingen roll att det är CSS vi använder, lagren är inte separerade på ett bra sätt här. Lösningen lider p.g.a. dessa likheter av (precis) samma problem som i det tidigare exemplet med en värld utan CSS.
Det blev ganska mycket text för något så enkelt som att associera två dokument med varandra, men slutasen är följande: använd externa stilmallar då det är möjligt. Punkt.
Du har redan sett några exempel på selektorer i introduktionskapitlet, bl.a. matchning efter elementnamn. Ibland är det inte nog med elementets namn och placering i trädet för att välja ut önskade element med selektorerna vi lärt oss hittills. Vi vill även i vissa fall att olika textstycken ska ha olika utseende, t.ex. kanske sammanfattningen till en artikel ska ha ett annat typsnitt än övriga texten. Lösningen till detta problem består av class- och id-attribut. Med dem kan vi märka ut vissa element som vi sedan kan matcha med en ny typ av selektor som vi introducerar snart. Attributen fungerar som alla andra attribut:
<p class="warning">Detta är någon typ av varning, som kommer att färgas röd senare med hjälp av CSS.</p>
<p>Detta är dock bara ett helt vanligt textstycke.</p>Att vi menar ett klassnamn och inte ett elementnamn i selektorn markerar vi genom att lägga till en punkt (.) framför namnet:
.warning {color:red;}Vi nämnde både klasser och något som kallades id. Vad är då id? Det är ungefär samma sak om klasser:
<p id="author">Stefan Kool</p>När du ska välja ut id:n istället för klasser med en selektor så skriver du nummertecken (#) framför namnet istället för punkt (.). Den enda skillnaden mellan klasser och id:n är att endast ett id är unikt i hela dokumentet. D.v.s. i hela dokumentet kan ett id endast förakomma högst en gång. Vad har vi för nytta av det då? Är id bara en dålig och begränsad klass? Begränsad, ja, dålig, nej. Det är att den är begränsad som gör den till ett lämpligare val vid vissa tillfällen. Att använda id:n istället för klasser bakar mer semantik i HTML–CSS-kopplingen, när vi ser:
#meny {color:green;}i CSS:en så vet vi att det är menyn. Tumregeln för att välja mellan huruvida du ska använda en klass eller id till ditt element är: om du vet att elementet endast ska förekomma maximalt en gång per dokument, använd ett id. Detta är för att CSS:en blir tydligare att läsa. När du ser selektorn #search i CSS:en så vet du att det är ”sökboxen” som varje sida har, medan om du ser .search kan det vara sökboxen, men det kan även vara något annat sökrelaterat, så du kanske måste kolla i några av HTML-dokumenten som använder aktuell stilmall för att se vad klassen används till.
Låt oss även ta detta tillfälle i akt och påminna dig om att det är viktigt att separera de två lagren. Det är viktigt att det inte finns information om presentation i struktur och betydelse-lagret. Om klass- och id-namnen innehåller information om hur elementen som bär dessa kommer se ut så läcker ju den informationen ut i fel lager. Följande exempel visar hur även detta kan reduceras till vårt första exempel i detta kapitel, där vi blandade de två lagren helt utan hyfs.
Låt säga att du vill att några av dina rubriker ska vara röda. Följande CSS-dokument kan tyckas vara lämpligt:
.red {color:red;}Ett utdrag ur något lämpligt dokument som visar användningen kan då se ut såhär:
<h1>En fantasilös rubrik</h1>
<p>Fantasilöst innehåll, som passar till den fantasilösa rubriken.</p>
<h1 class="red">En annan rubrik</h1>
<p>Ja, mer text.</p>
<h1>Ännu en rubrik</h1>
<p>Tror inte det finns mer att säga nu.</p>Det kommer lida av samma problem som vi tog upp tidigare, när vi kommer på att grönt är snyggare än rött så måste vi ändra alla class="red" till class="green", eftersom att om vi bara bytte ut CSS:en mot:
.red {color:green;}skulle vi skriva class="red" för att få grön text i ett element!
Vi får alltså inte nämna något om presentationen i HTML:en, inte ens i klass- och id-namn. Därför måste vi ha ett bättre sätt att namnge klasser och id:n. HTML handlar om semantik, så för att klass- och id-namn ska passa in där så måste även klass- och id-namnen vara semantiska. Vad betyder detta då? Jo, precis som HTML-element talar om vad innehållet är ska klass- och id-namn tala om vad elementen dessa appliceras på har för mening snarare än utseende.
Så vi måste ”ta ett steg bakåt” och se på varför vi ville göra texten röd från första början. Låt säga att det var för att du ville markera extra viktiga rubriker i din långa text (huruvida det är lämpligt att göra genom att ändra deras färg lämnas osagt …). Då borde important vara ett ganska beskrivande namn; det talar nu om vad elementet är tänkt att användas till/innehålla snarare än hur det är tänkt att se ut. important-klassen kan tilldelas vilka egenskaper som helst utan att vi behöver gå runt i alla HTML-filer och byta ut massor av text (en av de största fördelarna med CSS skulle ju försvinna annars).
Vid närmare eftertanke kan vi egentligen inte beskriva utseendet i textform i HTML-dokumentet heller (t.ex. ”ska bli röd med hjälp av CSS”) då detta skulle behöva uppdateras då vi byter ut färgen i stilmallen senare. Detta kommer vi dock ignorera i resten av denna bok (och har redan gjort några gånger) då det kan behövas i vissa fall när vi går igenom olika delar av CSS.
En annan trevlig sidoeffekt utav detta är att du måste tänka över varför du vill påverkar utseendet på en viss del av webbplatsen. Om du bara vilt delar ut olika kryptiska namn på klasser och id:n så kommer tillslut varken du eller dina besökare förstå vad din webbplats som nu är färggladare än en regnbåge försöker säga med sitt omotiverade färgsprakade. ”Varför är denna rubrik rosafärgad när ingen annan är det? Är det något speciellt med den?” är frågor som kan förvirra både dig och dina besökare, speciellt när svaret är något i stil med att du bara någongång kände för att ha lite rosa färg på din webbplats.
En naturlig fråga är som uppstår när vi letar efter lämpliga namn är vilka tecken ett klass- eller id-namn får innehålla? Det finns en rad komplexa regler för vad du får och inte får använda för teckenkombinationer, vi har valt att förenkla dem till:
Här följer några exempel på korrekta namn:
internets
agent007
use-hypens-instead-of-space-for-spacesoch här följer några som inte (repeterar: inte) är korrekta:
INTERNETS
007agent
-a-kewl-namedå den första innehåller versaler (”stora bokstäver”), den i mitten börjar med en siffra, och den sista börjar med ett skiljetecken.
(Dessa regler är något förenklade, HTML5 tillåter alla namn, HTML 4.01 har begränsningar på vad id får innehålla (det är HTML5 vi använder i denna bok som du säkert minns), medan CSS2 begränsar båda med en rad egna regler. Så det finns namn som egentligen är tillåtna även att våra regler säger inte är det, men det finns nästan aldrig någon anledning till att använda dem.)
Det börjar bli dags att introducera ännu några fler typer av selektorer.
Denna selektor är inte ofta så intressant, men kan vara bra att känna till. Den matchar alla element i trädet:
* {color: green;}Om du endast vill att t.ex. klassen test1 (id:n fungerar på samma sätt) ska matchas när den är knyten till ett p-element så finns följande tillgängligt:
p.test1 {color: green;}
h1.test2 {color: blue;}Om det appliceras på följande kommer endast det övre elementet matchas av någon selektor från ovan:
<p class="test1">Jag matchas av den första selektorn.</p>
<p class="test2">Jag matchas av inte av någon dock.</p>Du kan få nästlade element inom ett element med en viss klass (eller id) att bete sig på ett speciellt sätt, på ett liknande sätt som vi sett i introduktionskapitlet (lite repetition kommer förhoppningsvis inte skada). För detta använder vi syntaxten från förra stycket kombinerat med tidigare kunskaper:
p.example {color: green;}
p.example strong {color: blue;}<p class="example">Här kommer texten! <strong>Denna blåa text är viktig!</strong></p>
<p>En helt vanligt textstycke, <strong>inget att se här, jag är inte ens blå</strong>.</p>På den andra raden talar vi om att detta ska gälla för alla strong-element nästlade i p-element med klassen example. Nu kommer alltså alla strong-elementen inom p.example att få blå text, men inget strong-element utanför p.example kommer att påverkas. Som du ser så hjälper detta oss att få renare HTML-kod eftersom vi slipper onödiga id- och class-attribut. Ju färre class och id i koden desto bättre!
Det går att tilldela flera selektorer till samma block, följande CSS-kod:
h2 {color: blue;}
p#whatever {color: blue;}
p.footnote {color: blue;}skulle kunna förkortas till och fortfarande betyda samma sak:
h2, p#whatever, p.footnote {color: blue;}CSS tillåter oss välja ut delar med större noggrannhet än hela noder ur trädet, med pseudoelement kan vi välja ut delar av noder, så som det första tecknet eller första raden i ev. text som befinner sig i den noden. Pseudoklasser är främst av intresse när vi ska stila länkar, så de utelämnas tills vi tar upp sådana, de gör hursomhelst att vi kan bl.a. kan stila besökta och obesökta länkar på olika sätt.
Med pseudoelementen :first-line och :first-letter kan vi välja ut första raden resp. första tecknet. Detta är inte något som är överdrivet vanligt, men det är bra att känna till namnen pseudoelement och pseudoklasser. Syntaxen för både pseudoelement och pseudoklasser är följande (men bara pseudoelement används i exemplet):
p:first-line {color:red;}
p:first-letter {color:yellow;}Det finns en del selektorsyntax som väldigt sällan används, delvis för att webbläsarstödet saknas för vissa. Vi kommer inte nämna alla här, men en av dem är barnselektorn. Om vi skulle ha följande selektor:
body p {}Så skulle den matcha alla p-element som har body-elementet som förfader, så även de p-element som är nästlade i andra element skulle matchas. Om vi bara vill välja ut de p-element som är direkta barn till body-elementet finns följande selektorsyntax tillgänglig:
body > p {}En annan ovanlig selektorsyntax är attributselektorer, med dessa kan vi matcha element efter vilka attribut som är tilldelade till dem. Om vi bara vill matcha p-element med class-attribut (oberoende av värde för det attributet) kan vi använda:
p[class] {}Om vi vill begränsa oss ännu mera, och även anse värdet för attributet viktigt fungerar följande:
p[class="bar"] {}Det finns som sagt en del sällan använda selektorkonstruktioner, men de nämner vi inte här utan nöjer oss med länkar till CSS2-specifikationen och relevant CSS3-specifikation. Tabellerna på de båda sidorna fungerar mycket bra som referenser, men tänk på att många av dessa saknar webbläsarstöd. Ofta klarar du dig långt med de vanligaste selektorerna och slipper på så sätt problem med att vissa webbläsare saknar stöd. (När allt annat misslyckas brukar det lösa sig med några fler klasser och id:n på några element.)
En fråga som troligen uppstår efter att ha gått igenom så många olika typer av selektorer är vad som händer när mer än en regelmängd matchar ett specifikt element och alla dessa regelmängder innehåller t.ex. egenskapen color med olika värden. Vilken regelmängd bestämmer då vad texten får för färg i slutet? Föreställ dig följande:
h1 {color:blue;}
.important {color:red;}Applicerad på följande HTML-bit:
<h1 class="important">Japp, en rubrik till, efterfrågan är stor på sådana</h1>Det borde ju vid närmare eftertanke innebära någon kollision eftersom att fler än en regelmängd matchar h1-elementet i kodstycket. Vad bestämmer då om elementet blir blått (som h1-regelmängden säger) eller rött (som .important-regelmängden säger)? Det är här kastad – ja kaskad (eng: cascade) från ”Cascading style sheets” – kommer in.
Kaskad löser egentligen ett mer generellt är ovan nämnda. Som du mins så har webbläsaren en inbyggd stilmall som säger att bl.a. rubriker ska ha större teckengrad är textstycken och att allt text ska vara svartfärgad (CSS2-specifikationen har ett exempel på hur den stilmallen kan tänkas se ut, men använder en del egenskaper vi inte gått igenom ännu). Utöver det kan användaren av webbläsaren även ha en egen stilmall som appliceras på alla webbplatser (alternativt på utvalda), detta är (precis som det låter) inte så vanligt. Det kan användas t.ex. för att förstora texten på alla webbsidor om användaren har nedsatt syn eller om användaren i fråga är ett stort fan av limegrön kan all text färgas i denna oemotståndliga färg. Kaskaden talar hursomhelst om hur alla dessa kombineras ihop till ett slutresultat.
Innan vi kan gå in på hur detta går till måste vi nämna ännu en halvobskyr del av CSS, vi kan märka upp önskade egenskaper med !important för att ändra hur de hanteras i kaskaden (som vi kommer till snart), t.ex.:
h1 {color:red !important;}I vanliga fall behöver du aldrig använda denna funktionalitet, men med detta förklarat kan vi äntligen beskriva hur kaskaden går till. Beroende på var egenskapen kommer från anses de olika viktiga, ju högre nummer ju viktigare:
!important
!important
Så om webbläsaren säger att alla rubriker ska vara blåa, men du sedan säger i din stilmall att alla rubriker ska vara röda, ja, då vinner du och får bestämma. Vad händer då när två egenskaper från samma viktighetsnivå krockar? Kaskaden tar hand om även detta. Varje selektor tilldelas ett värde som kallas för specificitet, som kan sägas vara ett mått på hur specifik selektorn är. Dessa värden jämförs när det uppstår en krock, och den med högst specificitet får sista ordet.
Det något besvärliga här är att specificiteten inte är ett heltal, utan en sekvens utav fyra sådana. Så att jämföra två olika specificitetvärden är lite besvärligare än väntat, men det bör inte uppstå några större problem.
Vi har valt notationen (a, b, c, d), där a, b, c och d är heltal. Följande metod används för att beräkna specificiteten för en selektor:
style-attribut, blir a lika med 1, annars 0.
b är antalet id-selektorer (t.ex. #foo)
c är summan av antalet klassselektorer (t.ex. .foo), attributsselektorer (t.ex. p[class="foo"]) och pseudoklasser (vi har inte nämnt några ännu)
d är summan av antalet elementselektorer (t.ex. p) och pseudoelement (t.ex. p:first-letter)
Här följer några exempel.
| Selektor | Specificitet |
|---|---|
p
| (0, 0, 0, 1)
|
.baz
| (0, 0, 1, 0)
|
body.something
| (0, 0, 1, 1)
|
body#the-best-id-ever
| (0, 1, 0, 1)
|
p:first-line
| (0, 0, 0, 2)
|
html body#foo p.bar
| (0, 1, 1, 3)
|
Hur jämför vi två av dessa värden då? Jo, på samma sätt som vi skulle sortera ord i en alfabetiskt ordnad ordlista. Låt säga att vår ordlista är ganska fattig och bara innehåller orden ”giraff” och ”girig”, vilket av dem kommer först? Vi börjar så klart ifrån vänster och arbetar oss till höger tills vi ser något skillnad i tecken. Det första tecknet är samma, fortsätt till nästa. Även det andra är samma, fortsätt till nästa. Även det tredje är samma, fortsätt till nästa. Det fjärde tecknet skiljer sig dock åt i de två orden, då ”a” kommer före ”i” i alfabetet kommer ”giraff” före ”girig” i vår långa ordlista. Att jämföra två specificitetvärden fungerar på samma sätt, vi börjar från vänster och går till höger tills vi ser någon skillnad. När denna skillnad inträffar kontrollerar vi vilken av dessa två tal som har störst värde, och den mest störst värde får bestämma värdet för egenskapen som krockade. Följande är några värden ordnade efter stigande ordning: (0, 0, 0, 0) < (0, 0, 0, 1) < (0, 0, 0, 2) < (0, 0, 1, 0) < (1, 2, 3, 4).
Då flera selektorer med samma specifitet matchar ett element så bestämmer blocket till selektorn som deklarerades senast, t.ex. kommer alla textstycken bli gröna om följande CSS används:
p {color:blue;}
p {color:green;}Så, hur blir det med ursprungsproblemet? Kommer h1-elementet bli blått eller rött? Beräkna specificiteten för båda regelblocken (markera för svar: röd).
I nästa kapitel kommer vi gå igenom sida efter sida med olika egenskaper du kan tilldela dina element för att förändra utseendet på texten i dem, men än så länge nöjer vi oss med att introducera följande nya egenskap: font-size. Till den kan du tilldela procentvärden för att säga hur mycket större texten ska bli än i elementets föräldraelement (det finns en del andra sätt att säga hur stor texten ska bli men de sparar vi till det ovan nämnda kapitlet). T.ex. skulle följande göra alla h3-element onödigt stora:
h3 {font-size:150%;}Vad händer då om vi skulle göra följande:
h3 {font-size:150%;}
.foo {color:green;}<h3 class="foo">Ännu en rubrik</h3>Båda selektorerna matchar h3-elementet. Vi vet sedan tidigare att .foo har högre specifitet än h3 ((0, 0, 1, 0) resp. (0, 0, 0, 1)). Kommer då .foo-blocket att vinna över h3-blocket och rubriken kommer bli grön men oförändrad teckengrad? Det är inte så det fungerar! När flera selektorer till block matchar ett element så kommer egenskaparna från alla de blocken läggas ihop. Om en egenskap fanns i flera block kommer det blocket med högst specifitet att bestämma det slutgiltiga värdet. Så h3-elementet i exemplet kommer alltså bli både grönt och få större teckengrad.
Ett annat viktigt koncept när det kommer till CSS är arv. Kortfattat fungerar det så att barn till en nod ärver vissa av förälderns egenskaper, vilka dessa är går inte lika enkelt att sammanfatta. Vilka egenskaper som ärvs har valts ut så att det blir så naturligt för dig som utvecklare som möjligt. T.ex. så ärvs color-egenskapen, eftersom att om du säger att alla textstycken ska ha blå text vill du troligen även att alla t.ex. strong- och em-element i elementet även ska ha den färgen.
Oftast fungerar det bra att bara anta att det som är mest naturligt av huruvida arv kommer ske eller ej kommer att inträffa, men om det inte går som du tänkt dig så får du gå till CSS2-specifikationen som innehåller ännu en hjälpsam tabell. Kolumnen ”Inherited?” talar om ifall egenskapen ärvs eller ej.
Innan vi kan börja skriva en stilmall till webbsidan från föregående kapitel måste vi ta hand ett problem som följer av att vi använder HTML5 och att olika webbläsare tenderar att fungera på olika sätt. Alla webbläsare är inte redo för HTML5 så vissa extrasteg, i form av hack, måste göras. Det är inget ovanligt att vissa mindre hack måste utföras för att få specifika webbläsare att göra som du som utvecklare vill. Det är främst (som vanligt) Internet Explorer som bråkar. Vi kommer att använda html5shiv och html5resetcss.
html5shiv är enkelt att lägga in, det är bara att kopiera in följande inom head-taggarna:
<!--[if lt IE 9]>
<script src="http://html5shiv.googlecode.com/svn/trunk/html5.js"></script>
<![endif]-->Den första och sista raden är specialsyntax som gör att bara IE kommer att köra skriptet. Detta är ett element som associerar vårt dokument med saker från beteendelagret, så vi kommer inte gå in djupare på vad ovanstående gör.
html5resetcss fyller två uppgifter. Då olika webbläsare kan ha olika inbyggda stilmallar (det vi pratade om när vi behandlade kaskad, och för övrigt inte bara kan, de har det) kan olika webbläsare visa din webbplats på olika sätt. En stilmall som ger lämpliga standardvärden till alla element kallas för ”reset css”, eller återställningsstilmall. Det finns många färdigbyggda återställningsstilmallar, fast denna vi har valt åtgärdar även problem som uppstår när vi har med element från HTML5 som inte finns i HTML 4.01. Det vi ska göra är att koppla två stilmallar till varje webbsidan i fråga som vi ska stila, både din egen stilmall och återställningsstilmallen, webbläsare kommer sedan applicera båda dessa. Det krävs inga specialsteg för att ha fler än en stilmall på en webbsida, det är bara att lägga till ett nytt link-element. CSS-filen kan du ladda ner från html5resetcss-webbplatsen och spara den i samma mapp som dina andra filer.
Vi tar nu allt på en gång så att vi får ett skal att utgå från:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Grundmall för HTML5-webbsidor</title>
<!--[if lt IE 9]>
<script src="http://html5shiv.googlecode.com/svn/trunk/html5.js"></script>
<![endif]-->
<link rel="stylesheet" href="html5reset.css">
<link rel="stylesheet" href="din-stilmall.css">
</head>
<body>
<h1>Rubrik</h1>
<p>Text som vanligt.</p>
</body>
</html>På en verklig webbplats finns kan det finnas hundratals regelmängder, hur ska du kunna hålla koll på alla dessa? Svaret är att det finns verktyg som talar om vilka selektorer som matchar ett utvalt element och vilka egenskaper som har värden ändrade av dessa. Såvitt vi vet har dessa verktyg inget samlingsnamn, men vi har valt att kalla dem felsökningsverktyg. Vilka felsökningsverktyg som finns tillgängliga för dig beror på vilken webbläsare du använder, här följer en lista för några populära webbläsare:
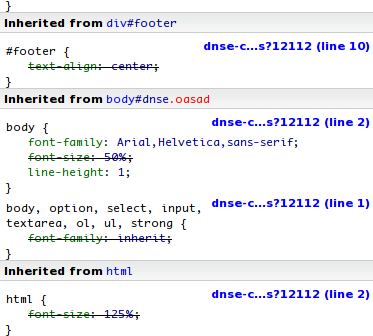
Se respektive manual för hur de ska användas. Följande bild visar ett element från dn.se, där Firebug talar om var olika egenskaper för ett element kommer från:
Nu kan du tillräckligt med CSS för att göra en del presentationsändringar för webbsidan från föregående kapitel. Börja med att skapa ett externt CSS-dokument och associera webbsidan med det, men glöm inte ovan nämnda fixar också. Du kan sedan testa att skriva några regelmängder med intressanta selektorer och se att de verkligen matchar de element du tänkte dig. Vi har ännu inte gått igenom så många egenskaper att ändra, så i nuläget får du nästan nöja dig med color. I nästa kapitel kommer vi som tidigare nämnt gå igenom en lång lista över egenskaper som påverkar textens uteende i valt element. Glöm inte att testa omkring med felsökningsverktyget du just installerade (t.ex. Firebug om du använder Firefox) och se så att kaskaden och arven fungerar som du tror.