
Sammanfattning: Detta kapitel beskriver HTML, det märkspråk som används för att beskriva webbsidors struktur och betydelsen hos de olika delarna på sidan. Vi påpekar även i detta kapitel vikten av semantik, och bygger upp en mycket enkel webbsida från grunden.
När du nu tagit dig igenom introduktionen är det dags att titta lite närmre på varje individuell del av de tre lagren. Det första (som behandlas i detta kapitel) är som bekant struktur och betydelse-lagret, som beskrivs med hjälp av märkspråket HTML. I nästa kapitel kommer vi bekanta oss närmare med presentationslagret, och dess språk CSS.
Vad HTML egentligen refererar till beror dock på sammanhanget det används i, HTML finns i flera olika varianter och versioner. Vi inleder därför med en kort historik som tar upp relationen mellan dessa.
Den första versionen av HTML utvecklades i början av 1990-talet av Tim Berners-Lee och några av hans kollegor på CERN i syfte att skapa ett sätt för forskarna att dela dokument över det som då var Internet. Det första riktiga förslaget till specifikation, ”HyperText Markup Language – A Representation of Textual Information and MetaInformation for Retrieval and Interchange” blev klart i mitten av 1993. Under dessa första år var HTML endast enkla förslag till standarder och implementerades lite godtyckligt av de få webbläsare som fanns.
Efter dessa första förslag satte standardorganisationen Internet Engineering Task Force (IETF) ihop en arbetsgrupp som skulle få lite bättre ordning på språket. Efter att ha arbetat med en standard i ett drygt år publicerades 1995 ett antal Request for Comments-dokument (RFC-dokument) som beskrev HTML 2.0. Det första av dessa var RFC 1866, som specificerade grunden i språket.
Nu var HTML på god väg att bli ett väldefinierat, och välanvänt, språk. År 1996 skapades World Wide Web Consortium (W3C) som tog över arbetet med standarden. W3C släppte HTML 3.2, som var något av en buggfix. Den inkluderade en rad tillverkarspecifika utökningar till HTML 2.0. Strax därefter, 1997, publiceras HTML 4.0. Denna version av HTML påbörjar arbetet med att separera struktur och presentation på allvar. Två år senare publiceras HTML 4.01, som är den senaste färdigskrivna versionen av HTML.
Därefter blir det mycket rörigt. Man bestämmer sig för att en XML-baserad version av HTML behövs, kallad XHTML. De senare versionerna av HTML var innan detta SGML-baserade, ett mycket komplicerat språk. XML är som SGML fast med färre komplicerade regler, vilket är tänkt att göra det enklare för utvecklare att webbläsare att förstå språket. SGML och XML är, något förenklat, två språk som kan användas för att definiera andra språk i, så som HTML. XML innebär även att det blir enklare att utöka (”bädda in andra format i”) sina dokument med andra XML-baserade märkspråk som t.ex. SVG eller MathML (märkspråk för vektorbaserade bilder resp. matematiska uttryck).
Den största skillnaden utöver att det är färre och enklare regler i XHTML än HTML ligger i felhanteringen. Ett XHTML får inte innehålla fel. Om ett webbläsaren stöter på ett fel när den tolkar ett XHTML-dokument så kommer tolkningen att avslutas och ett felmeddelande istället för webbsidan visas för användaren. Om däremot ett HTML-dokument innehåller fel så försöker webbläsaren laga felet och fortfarande visa webbplatsen för användaren. Detta gör det enklare för webbläsare men jobbigare för dig. Enligt oss är det som att vägra att läsa klart någon artikel p.g.a. att den skulle innehålla ett stavfel, när du lika gärna med stor chans att lyckas skulle kunna gissa vilket ord författaren egentligen menade. Varför görs detta då? Jo, det blir enklare att skriva tolkar för XHTML (och andra XML-baserade format) när ingen felhantering behöver göras.
XHTML baseras på HTML 4.01, och är i stort sett identisk förutom att språket är formulerat i XML istället för SGML. Denna standard spred sig snabbt bland webbutvecklare. Många hade dock dålig koll på vad XML egentligen innebär och hur det används (mer om detta senare), och därmed innebar XHTML inte någon förbättring, eftersom det inte användes på det sätt som var tänkt.
Nu är vi nästan framme i nutid, januari 2008. W3C publicerar i samarbete med Web Hypertext Application Technology Working Group (WHATWG) ett utkast till HTML5, nästa stora version av HTML. (Relationen mellan W3C och WHATWG är inte överdrivet enkel, så den utelämnas.) En kort notis här är att alla tidigare versioner av HTML har haft ett mellanrum mellan versionsnumret och HTML, inte denna dock. HTML5 (inte HTML 5 alltså!) innehåller mängder av förbättringar (även dessa kommer vi till senare), och tas emot med öppna armar. (Men mötte stora motgångar initialt i och med XHTML-anhängare.) Utvecklingen av nästa version av XHTML, XHTML 2.0, läggs sedan ner och istället satsas helhjärtat på denna nya HTML-version. Det är denna HTML du nu ska få lära dig. HTML5 är för övrigt varken definierat i SGML eller XML, det är bara HTML. Ordet HTML betyder i detta sammanhang ungefär ”på det sättet dagens webbläsare tolkar webbsidor”. Om så är önskas kan ett HTML5-dokument hanteras som XML och kallas då ibland för XHTML5. Vi kommer i denna bok inte intressera oss om XML, utan fokuserar på HTML5 i vanlig mening enbart.
Så vad menar vi då när vi säger bara ”HTML”? Oftast är det den senaste versionen av HTML som åsyftas, men ibland kan det vara XHTML. Se HTML som ett samlingsnamn för alla varianter av det, men som oftast refererar till den nyaste versionen.
XHTML ser mycket bra ut på pappret. Att det är enklare regler för webbutvecklare att följa och webbläsare att tolka. Att det är utökningsbart med andra XML-baserade format, vilket så klart är fördelaktigt.
Problemet är att många webbutvecklare inte vet hur det ska användas och webbläsarstöd saknas. Internet Explorer, som fortfarande är den mest använda webbläsaren stödjer inte XHTML (ja, stöd saknas helt!), vilket gör att man låser ute en stor del av sina besökare. Då HTML- och XHTML-dokument ofta är så pass lika kan dock IE tolka XHTML- som HTML-dokument, men då försvinner ju alla nya fördelar. I andra webbläsare saknas/saknades stöd för andra XML-format att bädda in i XML-baserade webbsidor, så inte heller där hade man mycket nytta av denna möjlighet.
Att det är simplare regler i XML än SGML visade sig inte hjälpa mycket heller. XML löste ett problem som inte fanns, webbutvecklare använder vanligen inte de avancerade delarna av SGML eftersom att de inte behövs (och webbläsarstöd ofta även saknades för dem). Så de nya XML-baserade dokumenten såg nästan likadana ut som de gamla SGML-baserade. För webbläsarna finns det inte heller mycket vinst här, eftersom att tolkningen av struktur och betydelse-lagret tillhör en av de minst krävande uppgifterna att tolka en webbplats, det är mycket tyngre för en webbläsare att rita ut webbsidan enligt presentationslagrets önskningar.
Vi sade att HTML 4.01 var den senaste färdigskrivna versionen av HTML. Vad betyder detta för HTML5? Även om HTML5 bara är ett utkast så stöds stora delar av HTML5 redan av nästan alla webbläsare, och stödet blir bättre och bättre för varje version som släpps. Detta handlar även om en attitydsskillnad mellan HTML5-gruppen och XHTML 2.0-gruppen. HTML5-gruppen går efter hur webben ser ut idag och vad webbläsare reda gör, XHTML 2.0-gruppen strävade istället efter en imaginär utopi där allt är vackert och färgglatt. Vi ser ju idag var de olika valen ledde till.
Eftersom denna bok satsar på att lära dig hur webbplatser utvecklas idag, är det mycket bra att även satsa på att visa dig hur det kommer att göras imorgon. Därför kommer du att få använda HTML5, men med fokus på de delar som fungerar i dagens webbläsare. När vi kommer till presentationslagret kommer en del sidoeffekter av att använda denna ickefärdiga produkt synas. Det viktiga att inse här är att olika delar av HTML5 är olika mycket färdiga. Det finns många delar med liten sannolikhet att de kommer ändras tills specifikationen anses vara klar och är därför redo för användning idag.
Nu när vi fått lite bakgrund, och framför allt förklarat varför det är just HTML5 vi ska använda, så kan vi börja skriva HTML. Eftersom detta kapitel endast behandlar struktur och betydelse kommer det inte se så snyggt ut, men det är den absolut viktigaste delen av boken. Utan struktur och betydelse fungerar inte webbens övriga lager, och det är därför mycket viktigt att lära sig bygga upp en bra struktur från början.
För att illustrera hur man gör detta kommer vi gå igenom uppbyggnaden av en enkel webbsida som replikerar divätemonoxid-bluffen, utifrån Snopes-varianten. Vi ska alltså bygga ett enkelt dokument andra kanske skulle skriva i ett ordbehandlingsprogam (så som Microsoft Word eller Writer från OpenOffice.org). Detta kommer att ge dig en bra uppfattning om hur man borde tänka när man bygger upp sin struktur. Vi börjar med en teknisk detalj.
Om du kollar på vilken välkodad webbsida som helst kommer du att i början av dokumentet förmodligen se texten <!DOCTYPE följt av en lång (eller kort) sekvens av tecken. Detta är en så kallad Document Type Declaration, och förkortas vanligen DOCTYPE. Innan HTML5 då HTML baserades på SGML var det viktigt att inkludera denna DOCTYPE. Den pekade på ett dokument kallat Document Type Definition (DTD) som beskrev ”grammatiken” i språket. I praktiken har DOCTYPE:n varit tämligen meningslös, eftersom de flesta webbläsarna redan har grammatiken ”inbyggd”. Istället använde webbläsarna den för att skilja på om webbsidan är kodad enligt moderna standarder eller gamla standarder, för att webbläsarna ska tolka en webbplats enligt moderna standarder måste varje webbsida fortfarande ha en. (Skillnaderna mellan hur webbsidan tolkas syns inte så mycket i det första lagret, det är presentationslagret som påverkas mest.) Inför HTML5 testade man ett antal olika varianter och kom fram till att den kortaste DOCTYPEn som fungerade i alla webbläsare var ”<!doctype html>” (om det är versaler eller ej spelar ingen roll), och bestämde därför att denna skulle användas. Av denna anledning måste alla dina HTML5-dokuments första rad innehålla denna DOCTYPE.
Om du inte redan startat din textredigerare så är det hög tid att du gör det nu. Vi börjar med att lägga upp grunden, som består av DOCTYPE:n och de tre element vi känner igen från introduktionen. Det bör se ut ungefär så här:
<!doctype html>
<html>
<head>
</head>
<body>
</body>
</html>Om du är en sån där otålig typ som vill se resultat kan du spara filen som t.ex. divätemonoxid.html och öppna den i en webbläsare. (Du får givetvis göra det även om du inte är otålig.) Du kommer säkerligen att bli besviken. Som du kanske anade har vi inte lagt in något innehåll alls i vårt dokument, och det kommer därför att vara ytterst minimalistiskt. Vita möss i snöstorm, någon?
Du vill säkert hoppa direkt på att fylla denna sida med en massa über-fantastiskt innehåll, men det får du vänta med. Först ska vi fylla head med metadata.
Metadata, från grekiskans μετά och svenskans data, betyder i korthet ”information om information” eller ”data om data”. Vad vi gör när vi fyller head med metadata är alltså att beskriva informationen som finns på webbsidan. I vårt fall kommer detta att bli trivialt; vi ska än så länge bara specificera en titel till vårt dokument och vilken teckenkodning som används för att spara filen. Vi börjar med teckenkodningen.
I introduktionskapitlet var vi begränsade till engelska för att det finns problem med å, ä och ö. Detta problem finns p.g.a. att det går att spara textfiler i olika teckenkodningar. För mer information om detta, se extrakapitlet Teckenkodning.
Vi kommer här nöja oss med att säga att du ska använda teckenkodningen utf-8 och att du talar om för din webbläsare vad som används genom att lägga till följande inom head-elementet:
<meta charset="utf-8">Hur du ändrar vilken teckenkodning som din textredigerare sparar filer i beror på vilken textredigerare du använder, se manualen eller leta runt i menyerna till du hittar var detta går att ställa in.
I vissa exempel så utelämnar vi meta-elementet som talar om vilken teckenkodning som används, för att spara plats (och delvis lathet).
Titeln definierar vi med hjälp av elementet title. Varje HTML-dokument måste ha ett och endast ett title-element. Detta elements innehåll är det som visas t.ex. webbläsarens titelrad, som titel för Google-resultat, och några andra saker. Viktigt att tänka på när man specificerar titeln är att den ska vara:
Titeln brukar oftast bestå av dokumentets faktiska titel (oftast den översta rubriken på sidan) samt webbplatsens namn. Ofta ser man titlar som t.ex. ”Fjortisbloggen » Idag köpte jag nya skor”, vilket är klart suboptimalt. Letar man efter denna sida i webbläsarhistoriken kommer man behöva läsa igenom halva titel innan man ens har en aning om vad sidan egentligen handlar om. (Sen ska man inte missbruka guillemeterna sådär, eftersom de är citattecken, men det är en annan sak.) En mycket bättre titel på ovan nämnda sida hade varit ”’Idag köpte jag nya skor’ på Fjortisbloggen”, eftersom man då först får informationen om vad dokumentet handlar om (vilket troligtvis är vad du vill veta), och sedan får information om vilken webbplats sidan tillhör.
I vårt dokument bestämmer vi oss för att titeln Bannlys divätemonoxid! är en bra titel. Vi lägger därför till ett title-element i head, så att vårt dokument nu ser ut så här:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Bannlys divätemonoxid!</title>
</head>
<body>
</body>
</html>Go ahead, spara och titta på den i en webbläsare – jag vet att du vill. Du kommer att blir lika besviken denna gång. Först nu ska vi börja lägga in riktigt innehåll i vårt dokument.
Det finns ett mycket bra engelskt uttryck som är viktigt att komma ihåg (oavsett hur man tolkar det): content is king. Utan innehåll skulle det inte finnas någon anledning att bygga webbplatser eller publicera dokument. Innehåll är det HTML egentligen skapats för, oavsett om detta råkar vara ren text, bilder, videor eller flashspel.
För att innehållet ska kunna tolkas ordentligt av de program som läser det är det viktigt att man märker upp sitt innehåll på ett vettigt sätt. I vårt enkla dokument kommer vi stöta på några av de viktigaste verktygen för att göra detta. Vårt dokument kommer endast att innehålla text, men vi kommer ändå att behandla många av de element du behöver för att märka upp ditt dokument på ett bra sätt. Låt oss börja.
Vi vill självklart att vårt dokument ska ha en rubrik. För rubriker fanns i HTML 4.01 elementen h1 till och med h6, som motsvarar sex nivåer av rubriker, där h1 är den översta nivån. Om du någonsin skrivit ett dokument som är längre än tre-fyra sidor är du nog redan bekväm med hur du bör använda olika rubriknivåer. För er som aldrig gjort detta (ni verkar vara överraskande många): grundidén är att ju större rubrik, desto viktigare är den. I de flesta fall ska man kunna bygga upp en hierarki av rubrikerna, och denna hierarki ska vara vettig; se till exempel bilden nedan.
HTML5 har tagit det här ännu länge. Istället för att vara begränsad till sex nivåer kan man nu i princip ha hur många som helst: man använder fortfarande elementen ovan, men nu kombinerar man dessa med element som t.ex. article och section. En artikel lägger man då lämpligtvis inuti ett article-element, och använder h1 för att märka upp artikelns rubrik, även om man redan använt h1 utanför article. Detta är något mer logiskt, och med dessa element skapar man tydligare grupperingar av innehållet på sidan. Vi lägger därför in vår rubrik i ett h1-element, omslutet av ett article-element:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Bannlys divätemonoxid!</title>
</head>
<body>
<article>
<h1>Bannlys divätemonoxid!</h1>
</article>
</body>
</html>Nu vill vi ju givetvis även ha med information om vem som skrev artikeln. Det känns väl som data som hör ihop med rubriken på något sätt, eller hur? Hur ska vi då ta med detta, vi kan ju inte lägga till det i h1-elementet, eller? Givetvis inte! HTML5 definierar även ett element som heter header. Detta element används för att märka upp allt som kan tolkas som ett huvud: i ett dokument är detta ett sidhuvud, i en artikel är det oftast rubriken med tillhörande information, och så vidare. I vårt exempel ska vi använda header för att omsluta artikelns rubrik och information om artikeln, så som författare och publiceringsdatum.
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Bannlys divätemonoxid!</title>
</head>
<body>
<article>
<header>
<h1>Bannlys divätemonoxid!</h1>
<p>Skriven av Nathan Zohner</p>
</header>
</article>
</body>
</html>Woah, woah, vänta lite här. Nu märker du säkert att vi har använt ett element vi inte berättat någonting om än: p. Detta element är nog det mest använda elementet i HTML, och representerar ett textstycke. Så fort du vill ha ett textstycke är det detta element du ska använda; det spelar ingen roll hur mycket text det är eller var den ligger – så länge det inte är en rubrik eller en lista (dessa kommer vi till senare) så ska det troligtvis ligga i ett p-element.
Nu vill vi kanske även specificera när dokumentet skrevs. För detta använder vi inline-elementet time. Ett inline-element är ett element som ligger i text, till skillnad från blockelement som skapar egna block. Inline-element används generellt när du vill göra något med orden i en text, till exempel berätta att det är en tid, visa att det är viktigt eller dylikt. I vårt fall vill vi alltså berätta att det är en tid av något slag.
Elementet time måste även innehålla attributet datetime. Ett attribut beskriver någon egenskap hos elementet, och i det här fallet ska datetime innehålla en maskinläsbar version av det datum som är skrivet inuti time-elementet. I vårt fall kommer det att se ut så här (notera att datumet inte har någon källa, eftersom vi hittat på det):
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Bannlys divätemonoxid!</title>
</head>
<body>
<article>
<header>
<h1>Bannlys divätemonoxid!</h1>
<p>Skriven av Nathan Zohner, <time datetime="1997-02-23">23 februari 1997</time></p>
</header>
</article>
</body>
</html>Bra. Men du, det här med underrubriker och taglines är ju coolt, kan vi inte ha med en sån också? Jovisst! Men nu måste vi tänka till igen: hur skulle man lägga in en sådan? Ska man kanske använda h2, det är ju typ en underrubrik? Nej, då får vi en ful hierarki. Lyckligtvis har HTML5 löst även detta problem: vi använder elementet hgroup för att gruppera rubriker, och på så sätt markera att vårt h2-element inte ska införa någon ny ”nivå”. Vårt dokument kan nu se ut såhär:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Bannlys divätemonoxid!</title>
</head>
<body>
<article>
<header>
<hgroup>
<h1>Bannlys divätemonoxid!</h1>
<h2>En av industrins farligaste kemikalier</h2>
</hgroup>
<p>Skriven av Nathan Zohner, <time datetime="1997-02-23">23 februari 1997</time></p>
</header>
</article>
</body>
</html>Okej, nu kanske vi ska lämna rubriken och tillföra lite innehåll. Gå till vår källa och översätt de två första styckena. Du får använda Google translate om du vill (men det kommer att se hemskt ut). Bra. Klistra nu in dessa som nya stycken direkt efter header-elementet. Det borde se ut så här:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Bannlys divätemonoxid!</title>
</head>
<body>
<article>
<header>
<hgroup>
<h1>Bannlys divätemonoxid!</h1>
<h2>En av industrins farligaste kemikalier</h2>
</hgroup>
<p>Skriven av Nathan Zohner, <time datetime="1997-02-23">23 februari 1997</time></p>
</header>
<p>Divätemonoxid är färglöst, luktfritt, smaklöst och dödar tusentals varje år. De flesta av dessa dödsfall orsakas av ofrivillig inandning av DVMO, men farorna med divätemonoxid slutar inte där. Långvarig kontakt med dess fasta form orsakar allvarliga hudskador. Symptom på DVMO-intag kan inkludera överdriven perspiration och urinering, och möjligtvis en uppblåst känsla, illamående, kräkningar och obalans i kroppens elektrolys. För de som blivit beroende leder brist på DVMO till säker död.</p>
<p>Divätemonoxid:</p>
</article>
</body>
</html>Uh-oh, nu händer något. Det är en lista ivägen. Hur märker man upp listor i HTML? Ska vi göra en massa stycken som börjar med punkter? Nej, självklart inte! HTML har sedan tidernas begynnelse innehållit två (egentligen tre, mer om detta snart) olika element för att skapa listor: ul för oordnade listor och ol för ordnade listor. Inuti dessa nästlar man sedan li-element. Detta element kallas på engelska för list item element och får det något löjliga svenska namnet listelementselement. Förvirrande? Ja. Poängen är i alla fall att varje punkt i listan har sitt egna li-element. Om vi överför (den oordnade) listan från källan till vårt eget dokument kommer det att se ut så här:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Bannlys divätemonoxid!</title>
</head>
<body>
<article>
<header>
<hgroup>
<h1>Bannlys divätemonoxid!</h1>
<h2>En av industrins farligaste kemikalier</h2>
</hgroup>
<p>Skriven av Nathan Zohner, <time datetime="1997-02-23">23 februari 1997</time></p>
</header>
<p>Divätemonoxid är färglöst, luktfritt, smaklöst och dödar tusentals varje år. De flesta av dessa dödsfall orsakas av ofrivillig inandning av DVMO, men farorna med divätemonoxid slutar inte där. Långvarig kontakt med dess fasta form orsakar allvarliga hudskador. Symptom på DVMO-intag kan inkludera överdriven perspiration och urinering, och möjligtvis en uppblåst känsla, illamående, kräkningar och obalans i kroppens elektrolys. För de som blivit beroende leder brist på DVMO till säker död.</p>
<p>Divätemonoxid:</p>
<ul>
<li>är även känt som hydroxylsyra, och är den största komponenten i surt regn.</li>
<li>bidrar till växthuseffekten.</li>
<li>kan orsaka allvarliga brännskador.</li>
<li>bidrar till erosionen av vår naturliga geografi.</li>
<li>accelererar korrosion och oxidering av många metaller.</li>
<li>kan orsaka elfel och minskad effektivitet hos bromsanordningar.</li>
<li>har påträffats i avlägsnade cancertumörer.</li>
</ul>
</article>
</body>
</html>Listor är en viktig del av HTML; det finns mycket som kan ordnas i listor, till exempel menyer, bilder (i t.ex. gallerier), definitioner, och mycket annat. Det finns som sagt tre typer av listor i HTML, numrerade, onumrerade och definitionslistor.
Numrerade listor ska användas när ordningen av delarna i listan är viktiga, t.ex. steg-för-steg-guider. Elementet för att märka upp listor heter ol och står för ordered list (sv. sorterad lista). Delarna i listan omges av li-taggar:
<h1>Morgonpass</h1>
<ol>
<li>Höger arm upp</li>
<li>Vänster ben åt höger</li>
<li>Knyt armarna runt magen</li>
<li>Lägg dig på golvet</li>
</ol>
Onumrerade används när ordningen inte är speciellt viktig, t.ex. vilka ingredienser som behövs till i ett matlagningsrecept. Istället för siffror brukar webbläsare visa det som punkter. Här är ett exempel på hur man använder onumrerade eller oordnade listor:
<h1>Ingredienser</h1>
<ul>
<li>En groda</li>
<li>Ett vänsterben</li>
<li>En kråka</li>
<li>Salt</li>
<li>Spiskummin</li>
</ul>Definitionslistor är ett specialfall; de är bra att använda till definitioner, t.ex. om man ska förklara olika ord eller liknande. Den har en annan struktur än den (o)ordnade listan: själva listelementet är dl, och sedan placeras titeln på definitionen i ett dt-element, som följs av definitionen i ett dd-element. Varje dd-element hör alltså till det dt-element som ligger precis innan (dess föregående syskon):
<dl>
<dt>Gris</dt>
<dd>Grisar är inte speciellt vanliga som husdjur.</dd>
<dt>Hund</dt>
<dd>Hunden brukar kallas människans bästa vän.</dd>
<dt>Katt</dt>
<dd>Katten har använts som sällskapsdjur ända sedan forntidens Egypten.</dd>
</dl>
Definitionslistor kan även användas till liknande fall, till exempel en dialog mellan två personer, där dt används för att märka upp namnen, och dd det personen ifråga säger. Andra områden det kan användas inom är att strukturera upp FAQs (vanliga frågor och svar) eller creditlistor, egentligen vad som helst som innebär ett samband mellan rubrik och förklaring, och där rubrikerna kan tänkas höra hemma i en lista. Det råder dock en något splittrad mening om vad man ska använda den underskattade dl till, vissa påstår att man bara får använda den till just definitioner, medan andra använder det till allt där rubriken och förklaringen har ett samband. Det brukar vara bra att lägga sig någonstans där emellan.
Notera att vi inte lägger texten i p-element, eftersom det inte är stycken, utan punkter i en lista. Oj, vad bra. Nu kan vi fortsätta. Vi ser att nästa stycke är fetstilt. Vad författaren egentligen vill uttrycka här är att det är viktigt. Vi kommer nu fram till två viktiga inline-element: em och strong. Det första, em, används när man vill visa att texten ska betonas. I webbläsare brukar detta visas genom att texten blir kursiv, men det är inget måste, och man ska absolut inte använda em om man specifikt bara vill uppnå kursiv text. Det ska man egentligen aldrig vilja (eftersom man beskriver struktur och betydelse, inte stil), så det ska inte vara något problem. Det andra elementet, strong, visar att texten i elementet är viktig. Detta brukar visas genom att texten blir fetstilt, men som ovan är detta inget man ska ta för givet eller ha i åtanke. (Man kan dessutom ändra dessa egenskaper med presentationslagret, som tas upp i nästa kapitel.)
I vilket fall som helst är det tydligt att vi vill använda strong. Vi måste dock fortfarande omsluta texten med ett p-element, eftersom strong inte ensamt beskriver att texten är ett stycke. Tekniskt sett skulle man kunna säga att dessa inline-element måste ligga i ett p-element (även om det råkar vara många ”nivåer” under i trädet), men det finns vissa specialfall där de kan ligga i andra element. Vi lägger in detta viktiga stycke och den efterföljande texten, och får fram ett någorlunda slutgiltigt resultat:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Bannlys divätemonoxid!</title>
</head>
<body>
<article>
<header>
<hgroup>
<h1>Bannlys divätemonoxid!</h1>
<h2>En av industrins farligaste kemikalier</h2>
</hgroup>
<p>Skriven av Nathan Zohner, <time datetime="1997-02-23">23 februari 1997</time></p>
</header>
<p>Divätemonoxid är färglöst, luktfritt, smaklöst och dödar tusentals varje år. De flesta av dessa dödsfall orsakas av ofrivillig inandning av DVMO, men farorna med divätemonoxid slutar inte där. Långvarig kontakt med dess fasta form orsakar allvarliga hudskador. Symptom på DVMO-intag kan inkludera överdriven perspiration och urinering, och möjligtvis en uppblåst känsla, illamående, kräkningar och obalans i kroppens elektrolys. För de som blivit beroende leder brist på DVMO till säker död.</p>
<p>Divätemonoxid:</p>
<ul>
<li>är även känt som hydroxylsyra, och är den största komponenten i surt regn.</li>
<li>bidrar till växthuseffekten.</li>
<li>kan orsaka allvarliga brännskador.</li>
<li>bidrar till erosionen av vår naturliga geografi.</li>
<li>accelererar korrosion och oxidering av många metaller.</li>
<li>kan orsaka elfel och minskad effektivitet hos bromsanordningar.</li>
<li>har påträffats i avlägsnade cancertumörer.</li>
</ul>
<p><strong>Föroreningen börjar närma sig epidemiska proportioner!</strong></p>
<p>Mängder av divätemonoxid har hittats i nästan varje bäck, sjö och reservoar i Amerika idag. Men föroreningen är global, och ämnet har till och med hittats i is på Antarktis. DVMO har orsakat skador för miljontals dollar i mellanvästern och nyligen i Kalifornien.</p>
<p>Trots farorna används divätemonoxid ofta:</p>
<ul>
<li>som lösnings- och kylmedel i industrin.</li>
<li>i kärnkraftverk.</li>
<li>i plastproduktion.</li>
<li>som brandskyddsmedel.</li>
<li>i många sorters grymma djurförsök.</li>
<li>i distributionen av insektsmedel. Även efter tvätt är råvaror täckta med denna kemikalie.</li>
<li>som tillsats i viss ”skräpmat” och andra livsmedelsprodukter</li>
</ul>
<p>Företag dumpar överblivet DVMO i floder och havet, och inget kan göras för att stoppa dem eftersom detta fortfarande är lagligt. Påverkan på djurlivet är extrem, och vi har inte råd att ignorera det längre!</p>
<p>Den Amerikanska regeringen vägrar att bannlysa produktionen, distributionen, eller användningen av denna farliga kemikalie på grund av dess ”vikt för den ekonomiska hälsan hos denna nation.” Faktum är flottan och andra militära organisationer utför experiment med DVMO, och designar maskiner för flera miljoner dollar för att utnyttja och kontrollera det i krigssituationer. Hundratals militära forskningscentra tar emot tonvis av det genom ett sofistikerat underjordiskt närverk. Många lagrar stora mängder för framtida användning.</p>
</article>
</body>
</html>Vi sparar nu detta med ett lämpligt filnamn (divätemonoxid.html som föreslogs innan är bra) och öppnar det i en webbläsare. Du kommer troligtvis att få se något hemskt, liknande detta:
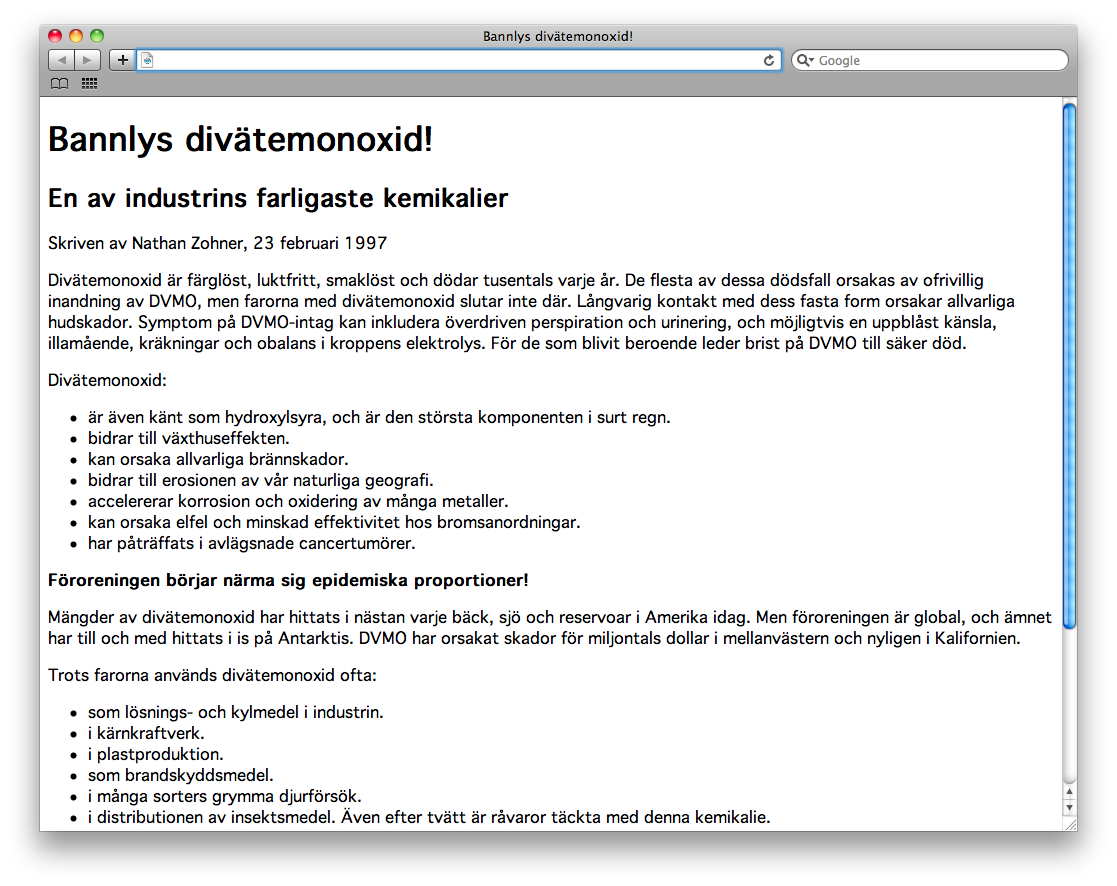
Fear not! I nästa kapitel ska du få lära dig använda presentationslagret för att göra detta något fula dokument alldeles underbart fint!
I detta kapitel har vi grundligt gått igenom det viktigaste inom HTML, som är basen i struktur- och presentationslagret. Det du bör ha lärt dig är följande: